Join us
@yonatankra ・ Jan 09,2022 ・ 11 min read・ 3k views ・ Originally posted on yonatankra.com







Here are 7 tricks with github actions that changed my life (or at least my CI/CD pipeline). These tricks helped me create a more maintainable workflows code as well as boosted performance of the whole CI/CD process.
If you haven’t used github actions before, you can watch my talk on how to setup CI/CD with github actions. This will get you up to speed real quick.
Now imagine you need to setup a massive CI/CD workflow. It starts with a Pull Request, which is usually the “first point of contact”. It then moves on to a post merge workflow. This post merge workflow splits into deploy, sanity or even multiple deployments. How would you trigger all of them? How would you synchronise them all? Github Actions triggers got you covered
#1: How to Use Github Action Triggers
Triggers is what starts a workflow. Here’s how it looks like:
The above code is pretty much self explanatory. The workflow will trigger on every pull request to the main branch. Not only that, it will also trigger for any push to the branch that is initiating the pull request.
This is a good place to run your tests, linting and all the automated QA you can think of.
Now that we have our Pull Request covered, we’d like to handle the code after the integration:
In the above code we trigger on push to main. This will usually happen after a pull request was merged (see Repository Integration Rules).
What happens after we push to main ? That's definitely up to you. You can run sanity checks, setup a canary deployment, deploy a next version of your app and more. You can even walk on the edge and deploy a stable version if all tests pass and you have enough confidence.
You might not yet be confident enough in the process to deploy on push to main. In this case, you’d probably want to give the code some time to “cook” in main or develop before you release a stable release. You can create a manual trigger in order to receive input from the user:
Here we setup a workflow manual dispatch that accepts an input "version". This way, a user can manually trigger a version bump from the Github web interface!
You just head over to the “Actions” tab, select the relevant action and the UI will take you from there:

Our workflow works great but… now it triggers on EVERYTHING that’s happening in the pull request.
Another cool feature that solves hard cases is the ability to condition the triggers even farther:
This code is the same example as the first, only now we state the type of pull request events we'd like to trigger our workflow for.
Another example is to listen to release tags:
Here we listen to tags that starts with the letter v as a convention to release tags.
You can find the full list of triggers and their API in the official documentation: https://docs.github.com/en/actions/learn-github-actions/events-that-trigger-workflows
Another way is by using an if statement in the jobs themselves:
Here we trigger on the PR’s close event. The job itself is fine tuning it a bit more — we’d like to trigger this for closed PRs, but only those with merged status.
Another conditional can be to not trigger certain jobs for drafts:
This will save us valuable computation time (and if you are a green person — also cut the CO2 emissions). I mean, if we set the PR as a draft, there’s no need to run all the heavy tests on it, right? Maybe just build and deploy a demo would suffice for a draft…
Armed with these tools, you can set the trigger to fit your need and build a full CI/CD flow (or actually, any automation). For instance, you can build iOS apps even if you do not have a Mac (by using a MacOS machine with a manual trigger).
#2: Reusable Workflows with Workflow Calls
Triggers are great, but this one gets a full title of its own.
Now let’s say you’ve created a build process. You also create a test process. Now — you’d like to run the build and the tests for 3 browsers — chrome, firefox and Safari. The catch? Safari runs only on MacOS. Darn…
So… you spin up 3 MacOS machines. You notice 2 things:
In addition, you need the test coverage only from the chrome run.
I think you got the gist of it — it can be complex.
So… you create 3 different jobs — one for each browser. Lots of code, not nice (you don’t really have to read the code — just get that it is long and not “nice”):
324 lines of code. WOW! Notice the section of the tests test-chrome, test-safari and test-firefox. They are practically the same except minor changes.
Now that’s a super-long and highly non-DRY piece of yml. All of this code that's repeating itself - if I need to make one change, I'd probably need to change all three jobs (another real, sad, story).
So… what can we do? When Github Actions started, we had an option to kind of automate this by using a Matrix. The matrix would set some variables and then permutate them. How many variables do we have here? Let’s see:
That’s 3 times 2 times 2. How does the matrix setup look like? Make sure you are sitting before you look at the code:
You see — we need to run on the two OS’s, but we need to exclude Safari runs on ubuntu while we need to exclude Firefox and Chrome on MacOS. In addition, we need to include the opposite. To top that, we need to include coverage report in Chrome. What a mess! The final code is really non-readable (meaning — hard to read, but we devs are highly dramatic):
So we still have an ugly file. Around half the lines of code, so it is a bit more maintainable. It is still hard to understand. What would we have done if it was our business logic code?
Split to Modules!!!
And this is where the Workflow Calls come into play. This API was introduced at a pretty late stage (around September 2021).
With workflow calls you can modularize your workflows into different files and call them from other workflows - just like you would a function or a module. You can even send parameters. So you see, our complex hardly maintainable code becomes much better:
The pre-release phase and its modules.
In the new modules code we have different files that can be called from anywhere. The build and lint workflow can be used both in the CD (as we see here) as well as in the CI. Same code - used twice.
Neat, ha?
#3: Speeding the Workflows with Caching and Artifacts
Great! we can trigger workflows. Now let’s speed them up a bit. The big hammer that gets the job done — that’s what I see in my mind when I think about caching. We have so many precise optimizations nowdays — but caching is by far the one that solves most of our performance issues while I believe it is the most primitive one.
Now the problem is this — you want to save time. Not only computation time costs money. Not only more computation creates more pollution. Longer processes cost time to… you! The developer who now has to wait until that stupid robot finishes its CI process.
So… a really quick optimization is to use caching. It can be as simple as caching the npm:
By using this super simple trick (cache: 'npm') we just told Github Actions to cache our npm file as long as our package.lock file is still the same.
You can do more complex caching using the cache action:
In the code above we used the cache action (uses: actions/cache@v2) in order to cache our yarn install process. The cache hash is set according to the yarn.lock file. If there's a cache hit, it will take that cache and use it.
In the installation step, we condition our installation in the absence of cache — so we install only if we need to. This can save MINUTES in every workflow!
You can achieve the same with artifacts:
Here we build our components in a multi repo (after we have everything installed) and then we gzip the whole folder and upload it as an artifact.
Then, anywhere in our workflows we can get our artifact and use a ready build and node_modules folder:
Much like a docker container ;)
This little trick will save you tons of running time both for build and for installations.
#4: Parallelism and Synchronous Operations
Jobs and workflows run in parallel by default. Steps run sequentially. So if you have one job that’s running:
yarn => yarn build => yarn lint => yarn test
You are good to go.
But, you’d like to do better than that. Let’s take the simple case of caching.
The build job:
yarn => yarn build => cache node_modules and build
The test job:
yarn => yarn test
The lint job:
yarn => yarn lint
The visual regression test job:
yarn => yarn build => yarn visual-regression
Now wait a minute — why run the install in all of them?
We could just create a job that installs and builds and caches that as we learned in the caching part. But… we also said that the jobs run in parallel. That means, we can’t tell if our installation and build finished before we get to the installation and build in the other jobs.
For this we have the needs property. It takes care of dependencies. That means, that if a job needs to run after a some build step, it will wait for it. We already saw it in the code snippets above. Let's look at the workflow_call example:
The call-lint-and-build is called first. The call-unit-tests depends on it and will start only when the build finishes. After the test we upload artifacts. The artifacts are later used in the call-pre-release.
Github actions creates diagrams for us and it looks like this:

Of course this is not an optimal solution for anything and just a show case, but you can play with it and use the principle to create the optimal solution for your use case.
#5: Repository Integration Rules
We have our actions setup. That’s cool. Now it’s time to use their super powers to enforce some laws.
With github actions, being part of github, it is super easy.
Settings => Branches => Add Rule
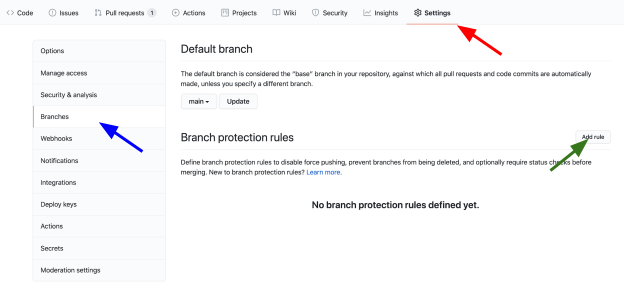
Here we’ll select Require status checks to pass before merging and check everything underneath it. You’ll see all workflows that are required to enable merge — in our case we only have build-test.
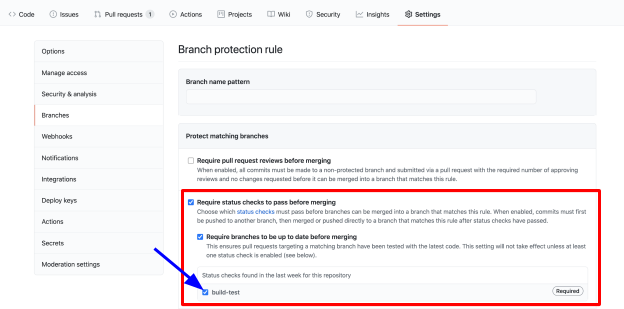
For Branch name pattern insert main and create the rule. And if you go back to the pull request page, you'll see that no pull requests can be merged before the tests pass, unless of course you have admin privileges.

#6: Saving Computation Time by Stopping Obsolete Workflows
We’ve optimized and safeguarded our CI/CD flow. Can we optimize more? Yes we can!
Let’s say you created a Pull Request. Our CI flow started rolling.
Now you forgot to add something in the code — you make a quick fix which takes 2 seconds and push it.
What happens now, by default, is that the old workflow keeps on running, while your last push initiated another one. That is resource wasting 101! How can we tell one workflow a new child spawned and it can stop?
The answer is: The Concurrency property!
By adding the concurrency and setting cancel-in-progress to true, github actions will search for a running process of the same group and stop it before starting a new one. How neat is that? Your devops team will LOVE you for it!
#7: Use Your Own Docker Image in Github Actions
Sometimes, you will have your own special needs. For instance, you will have your own setup or even proprietary software needed for compilation environment.
In this case, you might find it more useful rather than install all the dependencies (JAVA runtime, python, special language libraries etc.) just create a docker image of this environment. Then, when you upload it to a hub (e.g. docker hub) you can use it directly in your workflow:
The workflow above runs the visual regression checks. I wanted to set the browser versions as well as the playwright versions so as to have less flaky tests. This way, I’ll be able to run the tests locally on the same image it runs on during the CI.
I’ve created a docker image of my setup, uploaded it to docker hub and now I reference it in my yml file via the container property ( container: drizzt99/vonage:1.0.0).
This helps you twofold:
Summary
Github actions is awesome. It has its quirks, and it sometimes feels like a beta product. That’s true. But it also advances very fast and the time needed to setup even complex scenarios is relatively short.
I hope that with the tricks above you learned something new. I know this blog post will save me time in the future as I’ll get back to it to use these tricks again.
Thanks a lot to Yinon Oved for the kind and thorough review.
Share with your friends and followers
Join other developers and claim your FAUN account now!

Software Architect, Vonage
@yonatankra




Influence
Total Hits
Posts

Hand curated newsletters for Developers, private Slack with like minded people, podcasts, job offers, news and more!

