Introducing Headlamp Plugin for Karpenter
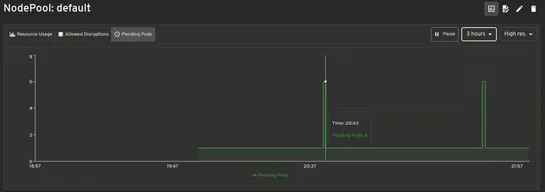
The newHeadlamp Karpenter Pluginwires real-time autoscaling insight straight into the Headlamp UI. It showsKarpenterresources, live metrics, scaling moves—no kubectl spelunking required. NodePoolsandNodeClaimsget mapped to core Kubernetes objects. You can tweak configs in the UI, get validation on t.. read more