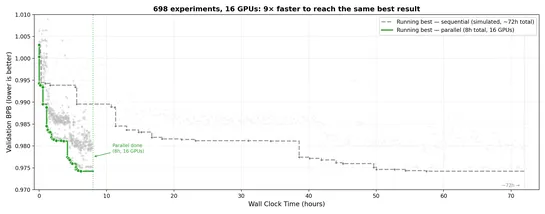
I built a programming language using Claude Code
Cutlet usesClaude Code. The LLM emits every line. Source, build steps, and examples live on GitHub. It runs on macOS and Linux and ships aREPL. It supports arrays, strings, double numbers, a vectorizingmeta-operator, zip/filter indexing, prototypal inheritance, and a mark-and-sweepGC. Development ra.. read more