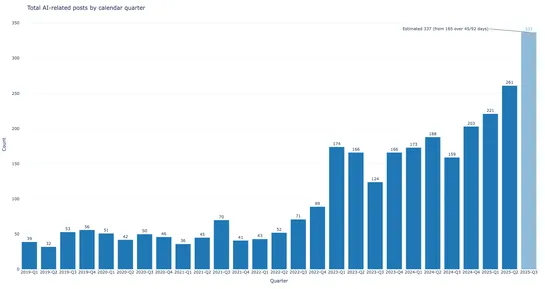
This New AI is 100x Faster at Reasoning Than ChatGPT
Sapient Intelligence’s HRM AI model challenges “bigger is better” in AI with a small 27M parameter design outperforming much larger models on reasoning tasks. The architecture mimics the brain, with a slow “planner” and rapid “worker,” achieving jaw-dropping results on benchmarks... read more