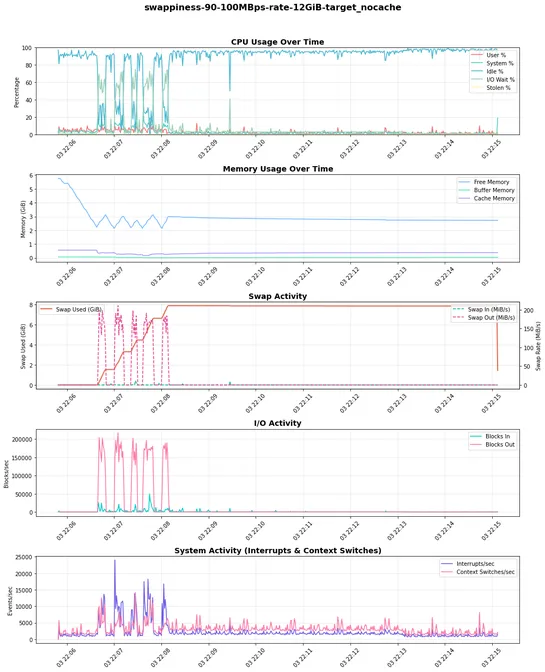
Tuning Linux Swap for Kubernetes: A Deep Dive
Kubernetes v1.34makesNodeSwapofficial. For the first time, swap on Linux nodes is fully supported—breaking with the old norm of just turning it off. Why it matters: NodeSwap gives the kubelet a pressure valve. Instead of firing off OOM kills, it can push some memory to disk. But this isn’t a free w.. read more