Debugging container image creation with a Dockerfile
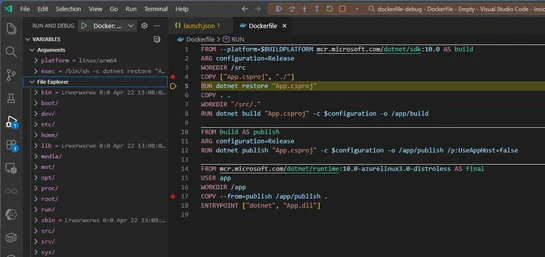
Docker just made debugging Dockerfiles inVS Codefeel like real development. With the latest Docker extension and Docker Desktop update, you can now set breakpoints, step through builds with F10/F11, poke at variables, and mess with the container’s file system mid-build... read more