Join us
@daloukalai ・ Jan 15,2022 ・ 7 min read ・ 2k views ・ Originally posted on faun.pub








At present Git is the most used “version control system” in the world, at the same time, a misunderstood and mechanically used tool for many too.
There are hundreds of articles and videos about it, but not many talks about its building blocks. They would be overly articulating about the usage and commands. Even if you go through the official documentation, you can only get the hang of usage but not the internals. Internals are fun to know and it will boost your confidence while you use the product. So in PART 1, I explain the internals in simple terms as usual. Let me see if I can do it.
GIT is Distributed Version Control System — What that means?
The creator of GIT is none other than Linus Torvalds. Hope you know his first product, the “LINUX Kernel” which is ruling the world. What else do you expect out of him? Just one more product to rule the world.
And first thing first! Git is just a “stupid content tracking tool” as expressed by the creator himself. How it was made as a “Distributed Version Control System” is sheer brilliance. It means, it does the following:
Centralized Vs Distributed
In a centralized repository, multiple versions of files is maintained in a central server. When people sync for the recent changes at some point, it downloads the very recent snapshot from the server. Later, if you want to go to any other previous version, you can fetch that from Central Server and replace it locally with the one you have. That means, at any point in time, just only one snapshot is present in your local machine.
In contrast, once you clone/pull, Git stores everything in its entirety in your local storage. Let’s assume you have 20 released versions of your repository, Git stores all those 20 snapshots in your local system and you can go back and forth without connecting to any server. I know you might be asking me like — “Wait! Let’s say my repo size is 5 GB and it stores 20 versions of it in my local repository, so it sweeps off 5*20 = 100 GB of my disc space?”. Actually no! That’s the beauty of Git. How Git stores and visualizes files really matters and that unique mechanism gives the power of distributed nature of it.
Hash & DAG — Keep these in mind.
Before getting into the Git object model, you must know the following about Hash:
Another concept to remember is DAG. DAG (“Directed Acyclic Graph”) is one type of graph representation without cycles. Tracking evolution is one of its use cases.
Git’s Object Model — Quick glance
On your git repository, you will obviously see the current working snapshot of your files. The rest all files of the multiple snapshots of your repository would be consolidated and represented in a hidden directory called “.git”.
Let me give a very quick overview of “.git" storage structure straight away.
All those mentioned are consolidated in that hidden “.git” directory present in your repository as I mentioned. That’s it! That’s the whole product. As I promised, I will not go further and this level of understanding is good enough to work with the product.
Some important “Reference Pointers” of GIT
Now we learned, if we just track the “commit” index, we can easily reconstruct a sub-tree of your DAG and that is your revision. How would you track it? It is again simple! Just with reference pointers. A reference pointer tracking a committed index is called “branch”. You can create as many branches as you can like “JIRA-123”, “stupidIdea”, “RTC-567” etc.
Irrespective of you creating a reference pointer, 2 reference pointers that you must know is HEAD & master. You are free to rename “master” as “main”, “development”, “virgin” or whatever. But “HEAD” remains “HEAD”.
master — It is a reference to the latest commit in the repository. This is also the first branch of a repository created by the git itself. Thus, it keeps tracking the latest snapshot in the repository.
HEAD — This is a “movable” reference pointer to a reference pointer. Mostly, it would be referencing “master” branch until switched. When “switch/checkout” is called, it will reference that particular branch.
In the below diagram, I have abstracted commit as single entity (it will be pointing to multiple blobs and trees internally) to illustrate how master and HEAD moves.
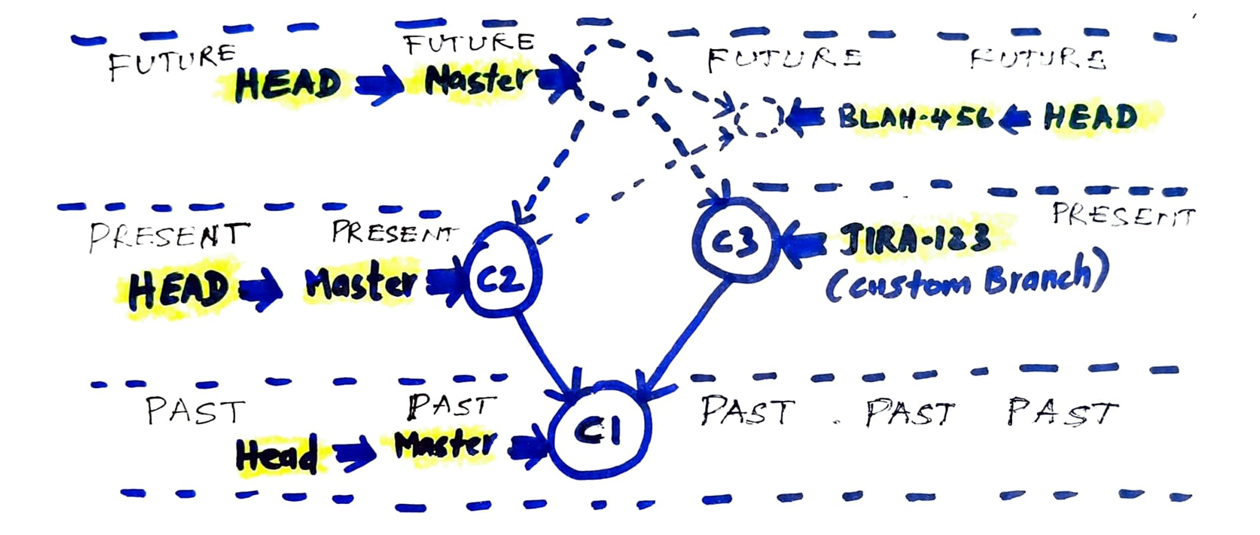
Fig 1: Illustration on How Master and Head moves
Just by using this simple idea, you can track the entire versions of your GIT repository.
Some GIT plumbing command examples
Actually, there is no need for you to know the plumbing commands. They are just fun to dig and re-verify what I spoke about just now. I am giving it here, feel free to omit this section.
It produces SHA-1 hash for a given text. The same is used by git internally. You can’t directly use this command, but can pipe it through the “echo” command as below:

The “objects” folder of git will find a new entry. git creates the first 2 “hex” as a folder name. The remaining 38 “hex” would be the file name. It is for easy indexing. It will appear as below:

2. git cat-file
If you open that file in a notepad, the content would be compressed. Don’t worry, you can unzip it with git cat-file as below:

Conclusion
Now I believe you have understood the basic building blocks of Git. It is nothing but hash-named blobs, trees, and commits connected as DAG. It had reference pointers at multiple places to reconstruct a snapshot. Thus, Git visualizes the file system in its own way to reconstruct it quickly. This magic happens just locally in a distributed way. That’s pretty much about this article. There is PART 2 cooking and it is on the way. In that, I promise, I will talk only from the user perspective and you can use Git confidently thereon. Catch you, until then C’ya!
Share with your friends and followers
Join other developers and claim your FAUN account now!





Influence
Total Hits
Posts

Hand curated newsletters for Developers, private Slack with like minded people, podcasts, job offers, news and more!


Only registered users can post comments. Please, login or signup.