







One of the defining features which make creating infrastructure in the cloud is resilience. The ability to create fault-tolerant structures which can stand the test of geographic and technical disasters. But how do you test that the architecture that you have created is fault-tolerant?
That is where Chaos Engineering comes in. It is defined as “A process that involves testing a distributed system to make sure that it can stand any failures in individual components”.
The idea behind Chaos Engineering is to introduce faults and try to break systems intentionally to see how the system responds and based on the findings, the system can be made more robust and fault-tolerant by fixing the issues.
Most major organizations organize Chaos Engineering game days where teams will try to break a system as a challenge, each uncovered fault means there is a flaw in the resilience of the system which needs to be fixed before an outage crashes it or a hacker can exploit it.
Probably the more famous example of a major organization using chaos engineering is Netflix. Netflix currently employs four full-time Chaos Engineers who routinely work on disrupting production environments.
Netflix has also created in-house software (Called Chaos Monkey) which does the same — throwing a monkey wrench in a perfect working environment and uncovers how the instances and the critical services react to disruption and testing if they have self-healing potential that saves millions down the line by patching vulnerabilities in advance.
AWS is not far behind in releasing the AWS Fault injection Simulator (FIS) service which allows you to introduce real-world scenarios and faults into your AWS environment in a controlled way.
AWS Fault Injection Simulator works by creating experiments — a set of rules that can test your environment. It can be load tests where AWS randomly increases the CPU and memory on the instances and see how they perform, simulating a natural change in traffic commonly seen during a sale or a shopping event or promotion.
Similar scenarios like the one we will test would be how the environment fares when one instance has gone “down” and simulating the response to downtime.
To get started with AWS FIS, search for FIS in the menu and click on the experiment template.

Give it a name and description and click “add” actions.

You will be greeted by many AWS-managed actions, for our scenario mentioned above we want to see how the environment will respond if a couple of instances were to be randomly shut down.

We then save the action, then add an action that makes FIS wait for 5 minutes so that we can monitor logs and see if there are scaling actions taking place to add the missing instances and consume logs for a better understanding of how the system behaves.

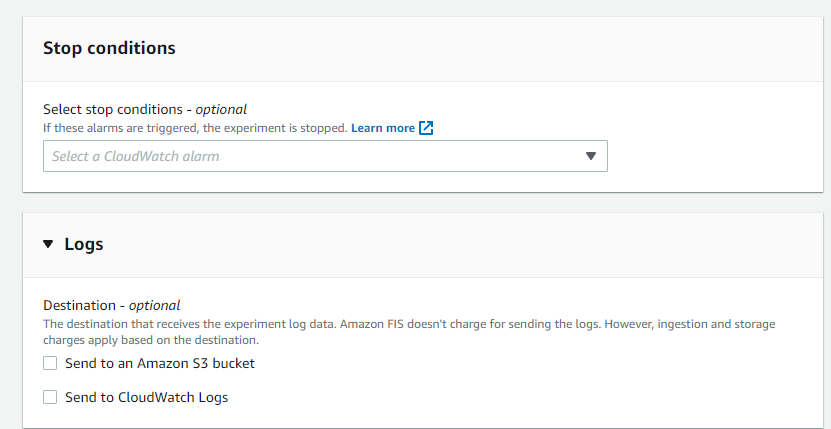
You can add stop conditions to stop the experiment controlling the level of disruption if you are running this in a Production environment (recommended). Additionally, you can configure logging allowing AWS FIS to automatically send the logs of the experiment on top of the logs you are actively looking at for the infrastructure.
AWS FIS lets you practice Chaos Engineering safely on your account, allowing you to get the benefits of knowingly tinkering with your account in a secure, monitored way and pinpoint gaps in the infrastructure, hidden points of failure or security lapses etc and work to rectify them resulting in a stronger, more fault-tolerant and resilient infrastructure.
Share with your friends and followers
Start blogging about your favorite technologies, reach more readers and earn rewards!
Join other developers and claim your FAUN account now!

BoldLink Sig
AWS DevOps Consultancy, Boldlink
@boldlink




User Popularity
862
Influence
86k
Total Hits
36
Posts





Read, Learn, Know, Teach
Hand curated newsletters for Developers, private Slack with like minded people, podcasts, job offers, news and more!

Only registered users can post comments. Please, login or signup.