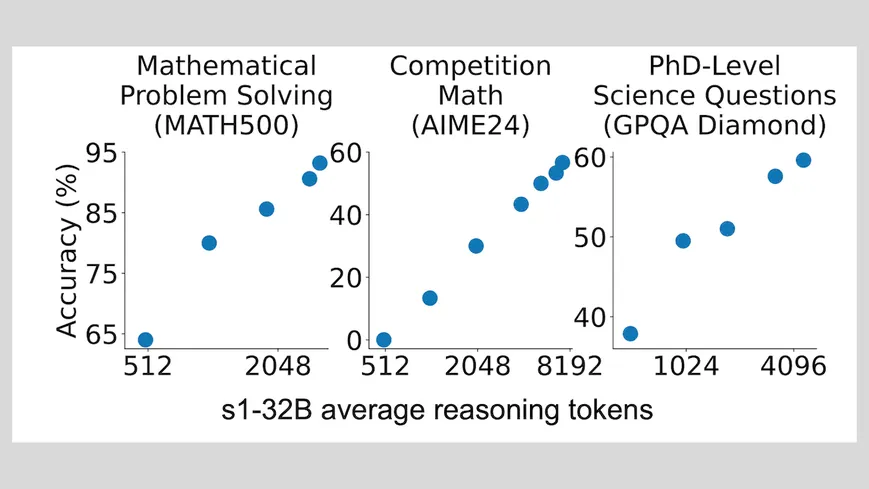
Meet the "Wait" token trick—a clever nudge that sharpens a model's reasoning. It mirrors OpenAI's o1-preview magic using only 1,000 examples. And guess what? Not a speck of reinforcement learning in sight.







Give a Pawfive to this post!
Share with your friends and followers
Start writing about what excites you in tech — connect with developers, grow your voice, and get rewarded.
Join other developers and claim your FAUN.dev() account now!








