







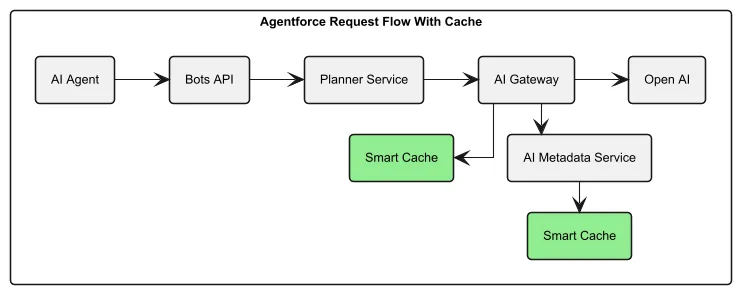
Salesforce’s AI Metadata Service (AIMS) just got a serious speed boost. They rolled out a multi-layer cache—L1 on the client, L2 on the server—and cut inference latency from 400ms to under 1ms. That’s over 98% faster.
But it’s not just about speed anymore. L2 keeps responses flowing even when the backend tanks, bumping availability to 65% during failures. Services like Agentforce stay up, even if they’re limping a bit.
System shift: What started as a performance tweak is now core to how Salesforce keeps its AI standing tall under pressure.








