







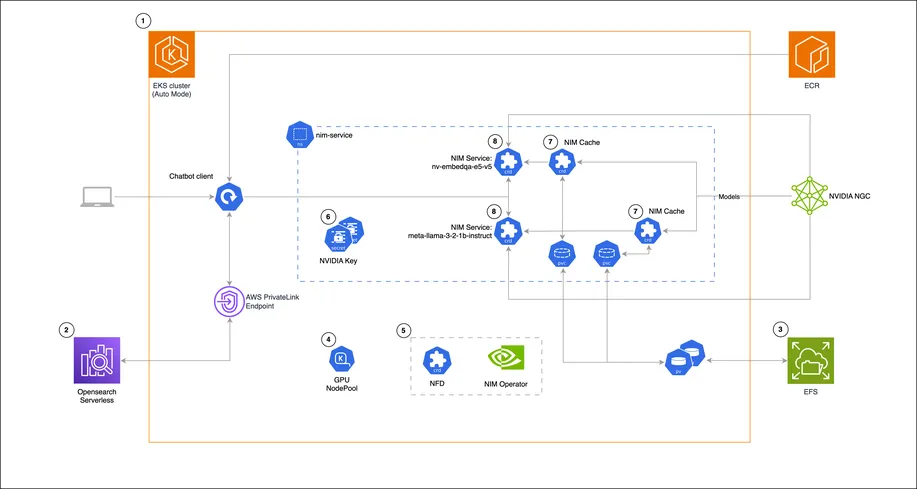
AWS and NVIDIA just dropped a full-stack recipe for running Retrieval-Augmented Generation (RAG) on Amazon EKS Auto Mode—built on top of NVIDIA NIM microservices.
It's LLMs on Kubernetes, but without the hair-pulling. Inference? GPU-accelerated. Embeddings? Covered. Vector search? Handled by Amazon OpenSearch Serverless. The cherry on top: NIM Operator takes care of deploying, scaling, and caching models inside your cluster.
What’s the play? Automate the gnarly parts of LLM ops. Chop down infra overhead. Ship modular AI apps that don’t creak in prod.








