Rails Logger: How to Customize, Configure, and Optimize Your Logs
Learn how to customize, configure, and optimize Rails Logger to improve logging and debugging in your application.

Learn how to customize, configure, and optimize Rails Logger to improve logging and debugging in your application.

This comprehensive guide explores the fundamental differences between Site Reliability Engineers (SREs) and Software Engineers, two critical roles in modern technology organizations. The article breaks down how Software Engineers focus on application development and feature implementation, while SREs bridge the gap between development and operations by ensuring system reliability and performance.
Key highlights of the blog include:
Detailed analysis of each role's core responsibilities and daily tasks
Comprehensive comparison of required technical skills and tools
Clear career progression paths for both positions
Decision-making framework for choosing between the two careers
The blog explains that Software Engineers primarily concentrate on coding, application development, and feature implementation using programming languages like Python, Java, and JavaScript. In contrast, SREs combine software engineering principles with operations, focusing on system reliability, automation, and infrastructure management.
Both roles require strong programming fundamentals, but SREs need additional expertise in areas like Linux systems administration, cloud platforms, and infrastructure as code. The article outlines career progression opportunities for both paths, from junior positions to leadership roles.
This comprehensive guide compares two leading monitoring and visualization tools: Grafana vs Datadog. The article provides an in-depth analysis of their features, capabilities, and use cases to help organizations make an informed decision based on their specific needs.
The comparison covers five key areas:
Monitoring Capabilities: Contrasts Datadog's comprehensive all-in-one monitoring solution with Grafana's visualization-first approach that supports monitoring through integrations.
Alerting Systems: Details Datadog's built-in alert management features versus Grafana's plugin-based alerting framework, highlighting the strengths of each approach.
Data Visualization: Examines how Datadog offers user-friendly, pre-built solutions while Grafana provides highly customizable visualization options.
Integration Ecosystem: Compares Datadog's 600+ built-in integrations against Grafana's flexible plugin architecture and community-driven ecosystem.
Pricing Structure: Analyzes the cost implications of choosing between Datadog's SaaS model and Grafana's open-source approach with optional paid features.
The article concludes that both tools excel in different scenarios: Datadog is ideal for organizations seeking a comprehensive, ready-to-use monitoring solution, while Grafana is perfect for teams that prioritize visualization flexibility and have existing monitoring tools in place.
Looking for a Pingdom alternative? Explore the 7 best website monitoring tools for better insights, uptime tracking, and performance optimization.

The blog explores Site Reliability Engineering (SRE), a discipline that combines software engineering and IT operations to build scalable, reliable, and efficient systems. Originating at Google, SRE has become a critical practice for modern IT operations, ensuring systems remain robust and performant even under high demand. The blog delves into the core principles of SRE, such as embracing risk, setting Service Level Objectives (SLOs), automation, monitoring, and incident management. It highlights the role of SREs in designing reliable systems, optimizing performance, and fostering collaboration between development and operations teams. The blog also outlines the benefits of implementing SRE practices, including increased reliability, cost savings, and faster incident resolution. Finally, it provides actionable steps for organizations to adopt SRE, emphasizing the importance of automation, monitoring, and a blameless culture.
Explore the key differences between Kubernetes Pods and Nodes to better understand their roles in container orchestration.
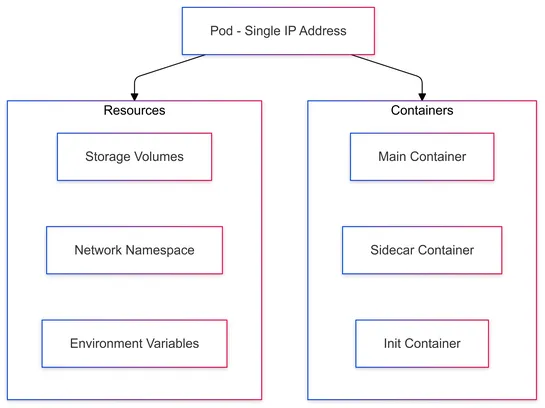
Learn advanced kubectl exec techniques in Kubernetes, covering best practices for troubleshooting, security, and resource management.

Discover the key differences between OpenMetrics and OpenTelemetry, from scope and use cases to adoption and flexibility, to make an informed choice.

Learn about the 5 common incident severity levels and how they impact your response to system issues, ensuring faster resolutions.

Syslog levels help categorize log messages by severity, making it easier to monitor, troubleshoot, and prioritize system events.


