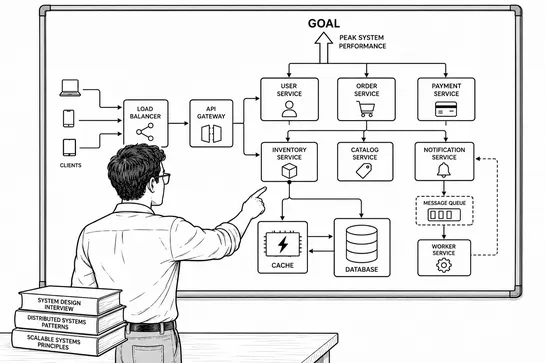
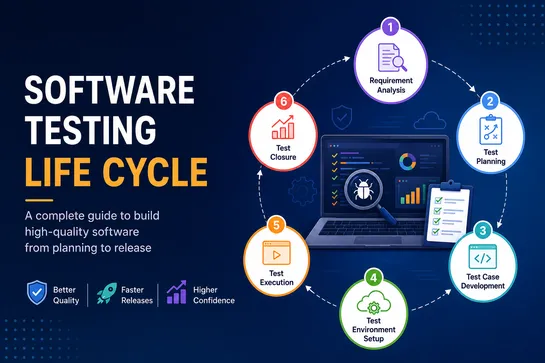
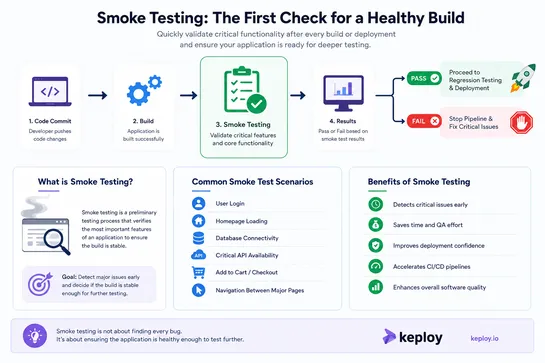
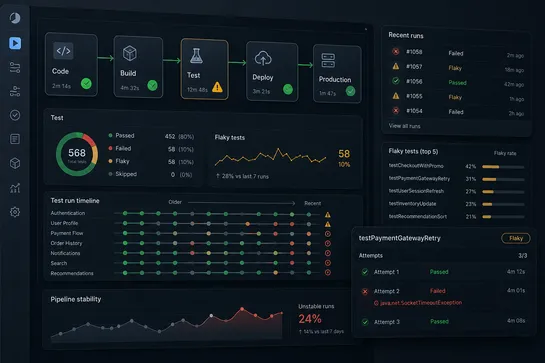
Why Businesses Are Moving from Generative AI to Agentic AI Systems?
Businesses are shifting from Generative AI to Agentic AI systems because modern enterprises need more than content generation; they need AI that can think, plan, make decisions, and execute tasks autonomously. Agentic AI enables smarter workflow automation, faster decision-making, reduced manual effort, and improved operational efficiency across industries. As businesses focus on scalability and intelligent automation, Agentic AI is emerging as the next evolution of enterprise AI solutions.