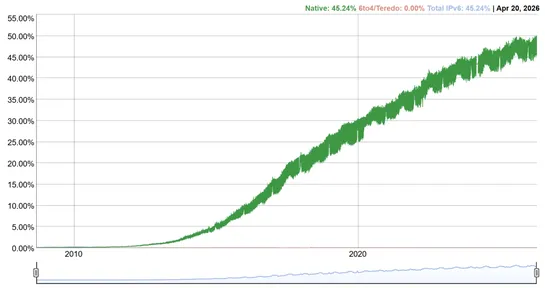
Google hits 50% IPv6
The 50% IPv6 milestone is real, but adoption differs by country. Analysts who report lower figures use population-weighted sampling, while their per-country adoption rates match the higher estimate... read more
Join us

The 50% IPv6 milestone is real, but adoption differs by country. Analysts who report lower figures use population-weighted sampling, while their per-country adoption rates match the higher estimate... read more
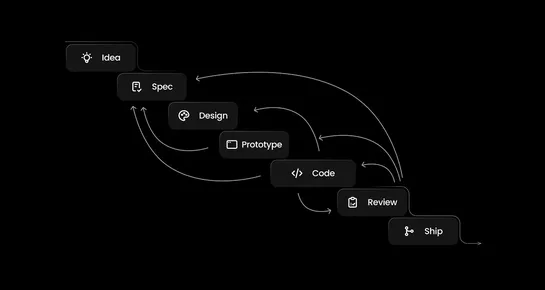
The speed of innovation is crucial for teams, and AI tools have enabled faster work. A collaborative coding model where teams build, review, and ship alongside AI agents is key to staying ahead in workflows. Three shifts have reshaped how teams build, leading to the adoption of a new collaborative c.. read more

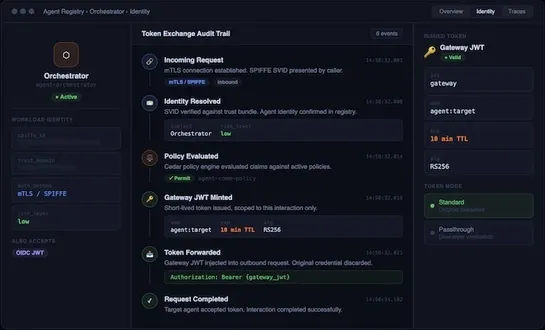
Tigera launched Lynx for general availability, a Kubernetes-native control plane that operators place in the path of AI agent calls so teams can enforce identity and policy... read more
Netflix migratedmillions of batch jobsfrom their custom queuing system toKueue, a cloud-native job queueing system, as part of transitioning to a more Kubernetes-native infrastructure. Kueue offers features such as preemption, fair sharing, and hierarchical tenants that were missing in their homegro.. read more
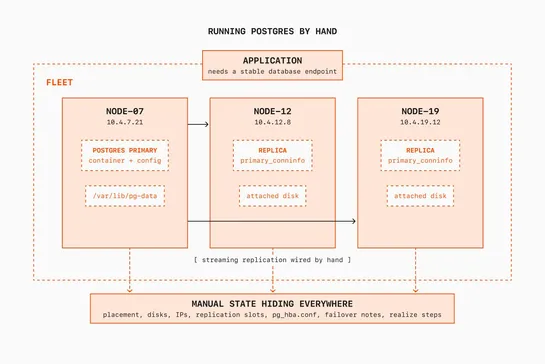
Datadog made PostgreSQL failover safer by treating replica lag as the promotion gate. A zonal-failure gameday showed that detection and automation could not protect the database if the standby sat behind the primary. The team added lag-aware checks, clearer operator signals, and failure drills so en.. read more

Designing Kubernetes manifests with mixed configurations can lead to unpredictability in how resources are managed between containers. This is due to the different ways Kubernetes and Linux handle requests, limits, and OOM situations. To avoid operational risks and ensure stability, it is crucial to.. read more

The recent shift towards Kubernetes adoption can be attributed to the benefits of uniform deployment, standardized knowledge, and traceability it offers. With managed K8s services maturing and Helm simplifying deployment, more companies are choosing Kubernetes regardless of their technical needs. Th.. read more
Kubernetes operatoris a closed feedback loop that ensures desired state for running workloads, similar to a thermostat's control. Operators automate manual tasks in managing databases like Postgres, improving efficiency by comparing and converging states. The same loop structure in a Bash script can.. read more

When an LLM reads "here's some text, here's a criterion - does it satisfy it?", the answer often already exists in its hidden state before it generates a single token. So skip generation entirely: grab the hidden state at the last prompt token (~70% of the way up the model's layers), feed it to a ti.. read more
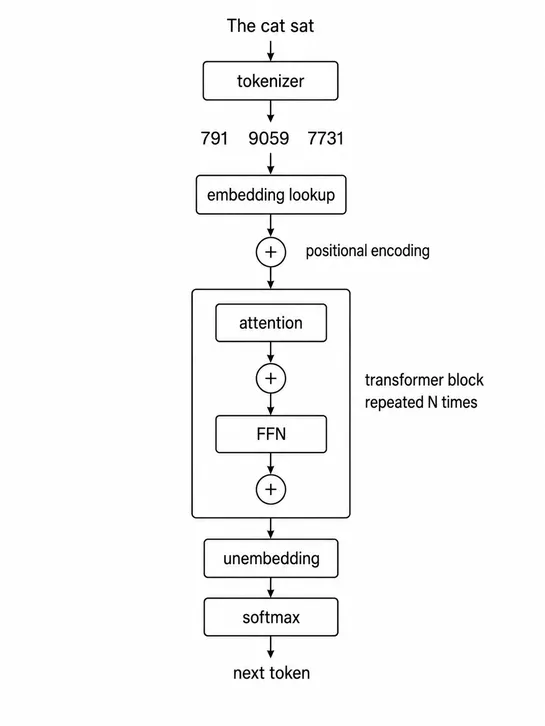
This post covers the core mechanisms inside modern transformer-based LLMs, including tokens, embeddings, positional encoding, attention, multi-head attention, and more. Tokenization converts text into integer IDs, embeddings give tokens meaning through vectors, and positional encoding helps the mode.. read more