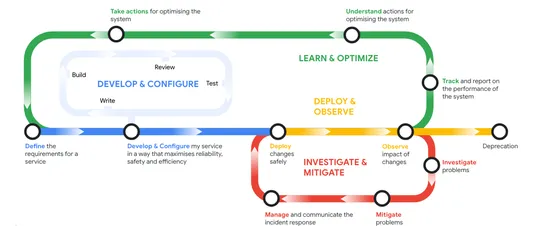
How Google SRE is using agentic AI to improve operations
Google SRE authors argue that teams should use agentic AI across the reliability lifecycle and give agents clear controls and audit logs before they allow them to change production state... read more