Top 7 Python Libraries for Large-Scale Data Processing
This article covers Python libraries that make large-scale data processing faster, more scalable, and easier to manage across modern data workflows... read more
Join us

This article covers Python libraries that make large-scale data processing faster, more scalable, and easier to manage across modern data workflows... read more

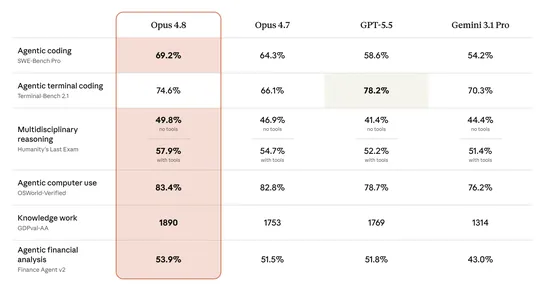
Claude Opus 4.8 delivers top-tier performance with honest and powerful collaboration, outpacing prior models and GPT-5.5 across multiple benchmarks. Opus 4.8's cutting-edge abilities and improved judgment set a new standard for enterprise AI, enhancing reliability and reasoning quality, ready for im.. read more
Perplexity's engineers introduced Search as Code, and developers use its Python SDK to call low-level retrieval primitives instead of sending queries to one search endpoint... read more


Intel designed Crescent Island, an AI inference GPU, with lower-cost memory and air cooling, and plans to ship limited quantities this year... read more

DevOps metrics show how fast & reliable your team delivers software; valuable for saving money & building trust.DORA metricsonly part of the picture. Focus on key categories to understand if overall delivery is improving. Don't just measure, find the bottleneck for real improvement... read more

A researcher disclosed CIFSwitch, a Linux local privilege escalation flaw present since 2007. Unprivileged users can exploit the CIFS Kerberos mount helper to gain root access... read more

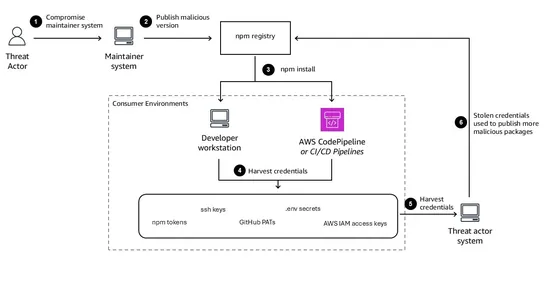
AWS security teams define npm supply-chain defense as two tasks: limit credential blast radius and block unverified artifacts before production... read more
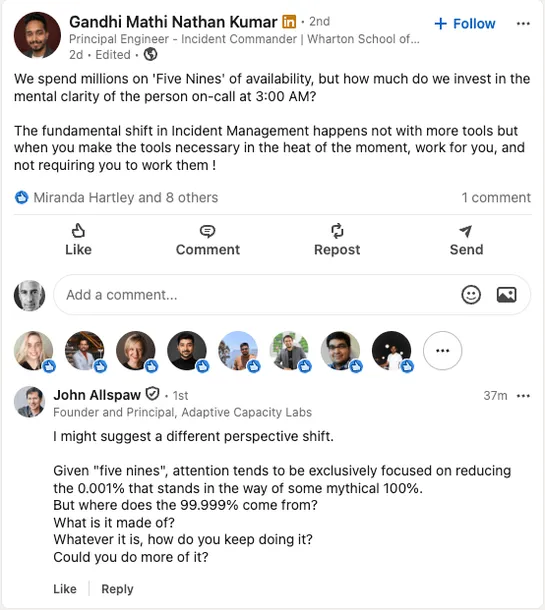
SREs should study how engineers keep systems reliable during routine work, including the adjustments they make before incidents occur. Tech teams have adoptedSafety-IIat a limited rate because they lack practical models for observing those adjustments... read more


Learn how to build powerful AI agents on AWS MCP Server. A complete guide covering setup, architecture, tools, and real-world use cases.


