Terraform Production Readiness Cheatsheet

Terraform working isn’t enough. Learn what it takes to make it production-ready — from backend design to security and automated pipelines.
Join us


Terraform working isn’t enough. Learn what it takes to make it production-ready — from backend design to security and automated pipelines.




")
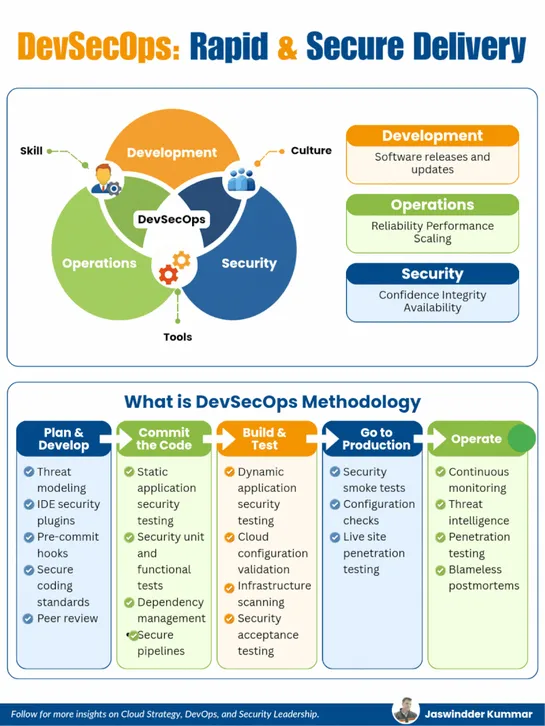
If security is your last step, you’re already too late. This guide shows how to build a DevSecOps pipeline where security is continuous, automated, and invisible to delivery speed.

GitHub revoked Copilot's ability to inject tips into other users' pull requests after reports that Copilot Review inserted aRaycastlink. They disabled agent tips in PR comments, blamed a programming-logic bug, and said they won't turn tips into ads... read more

SQLite packsJSONextraction, expression indexes,FTS5full-text search,CTEs, window functions, andWALinto a single file. It enforcesstrict tables, supportsgenerated columns, and indexes JSON expressions for fast semi-structured queries... read more
CTO at ZAR shares his experience managing 10 engineers, shipping code, and operating at the C-level with an AI assistant named Claude Code. The system allows him to maintain context across multiple workstreams, automate tasks, and scale his productivity. In just three weeks, he has documented 82 mee.. read more
Python 3.3 introduced three key features that have had a lasting impact on Python development. Firstly, yield from simplified the composition of generators by allowing easy delegation between them. Secondly, venv standardized virtual environments in Python, improving isolation and reproducibility of.. read more

The article catalogs obfuscation methods:HTML entities,SVG in an object,display:none, JavaScript decoders, custom encodings, andAES‑256. It coversmailtoobfuscation, redirects (302/301,.htaccess), interaction-gated reveals, accessibility caveats, and ahoneypot-based spam-statistics system... read more

