The Big LLM Architecture Comparison
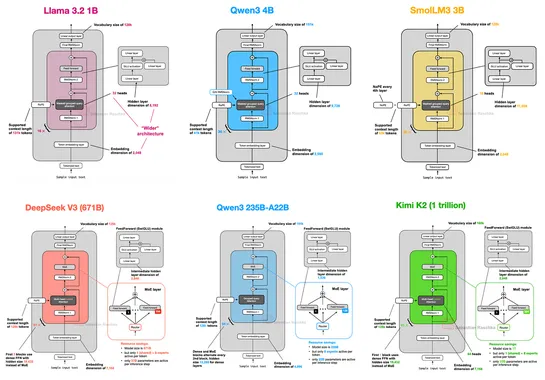
Architectures since GPT-2 still ride transformers. They crank memory and performance withRoPE, swapGQAforMLA, sprinkle in sparseMoE, and roll sliding-window attention. Teams shiftRMSNorm. They tweak layer norms withQK-Norm, locking in training stability across modern models. Trend to watch:In 2025,.. read more