Advanced PostgreSQL Indexing: Multi-Key Queries and Performance Optimization
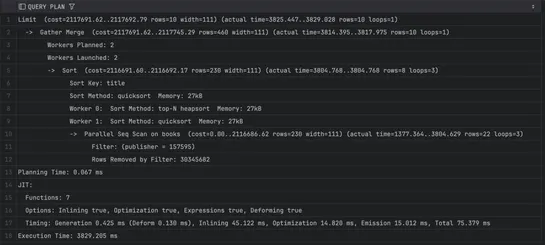
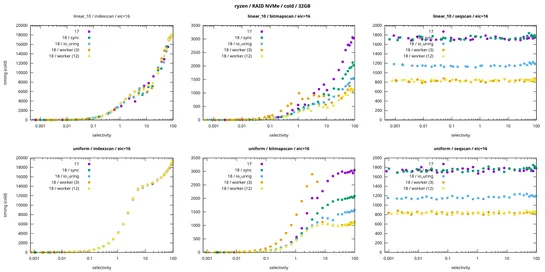
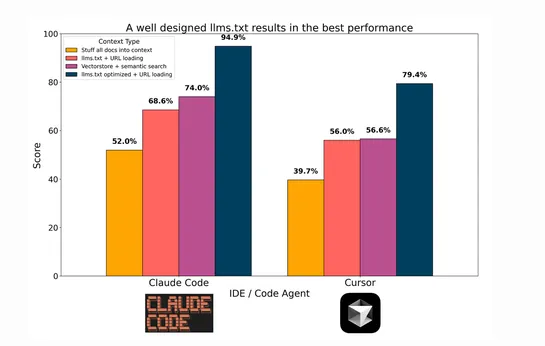
Advanced PostgreSQL tuning gets real results: composite indexes and CTEs can cut query latency hard when slicing huge datasets. AddLATERALjoins and indexed subqueries into the mix, and you’ve got a top-N query pattern that holds up—even when hammering long ID lists... read more