Announcing etcd v3.6.0
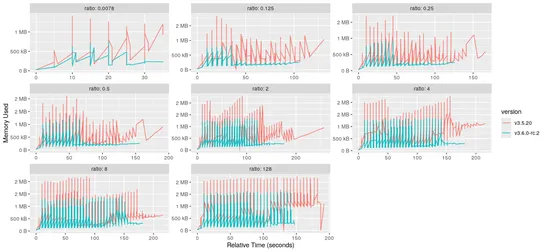
etcd v3.6.0slashes its memory footprint by half, ditching v2store like yesterday's leftovers. Performance leaps by10%, powered by a string of clever tweaks. Kubernetes-style gates now govern upgrades; they promise to tame chaos but may demand a secret handshake... read more