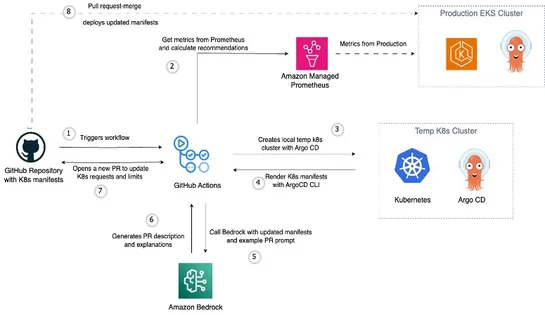
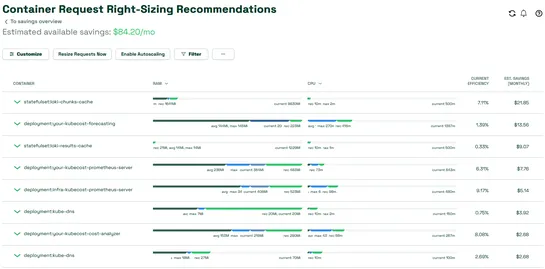
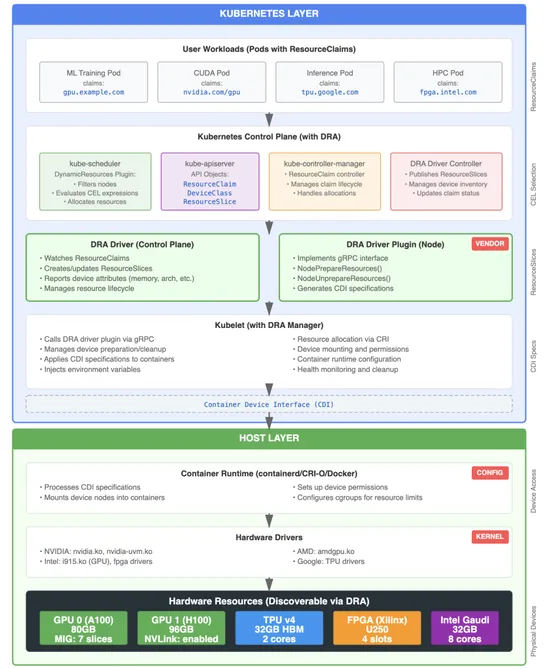
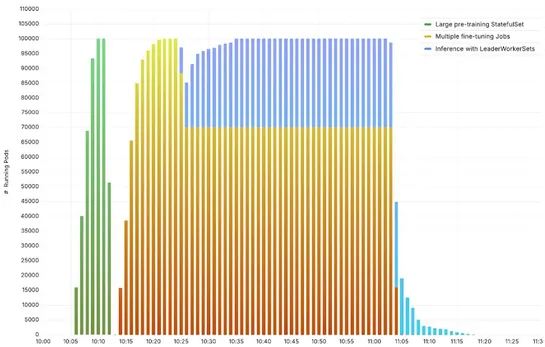
Paused Kubernetes project finds path forward
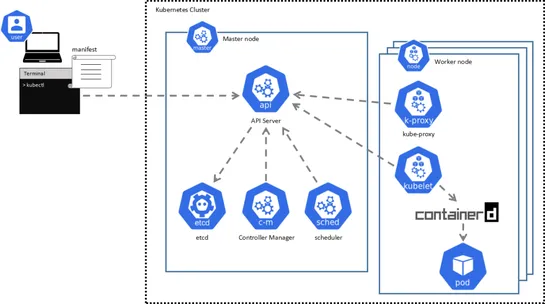
TheExternal Secrets Operator (ESO)is moving again. After hitting pause from maintainer burnout, it’s back under CNCF incubation—with a rebooted structure in place. New governance, clear contributor paths, and support tracks for CI, core dev, and testing are all in. But don’t expect fresh releases ju.. read more