walrus: ingesting data at memory speeds
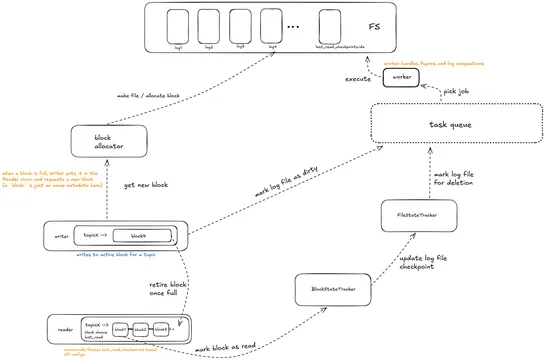
Walrusis a lock-free, single-nodeWrite Ahead Log in Rustthat rips through a million ops/sec and moves 1 GB/s of write bandwidth - on bare-metal, nothing fancy. It leans on mmap-backed sparse files, atomic counters, and zero-copy reads to get there. Each topic gets its own line of 10MB memory-mapped .. read more