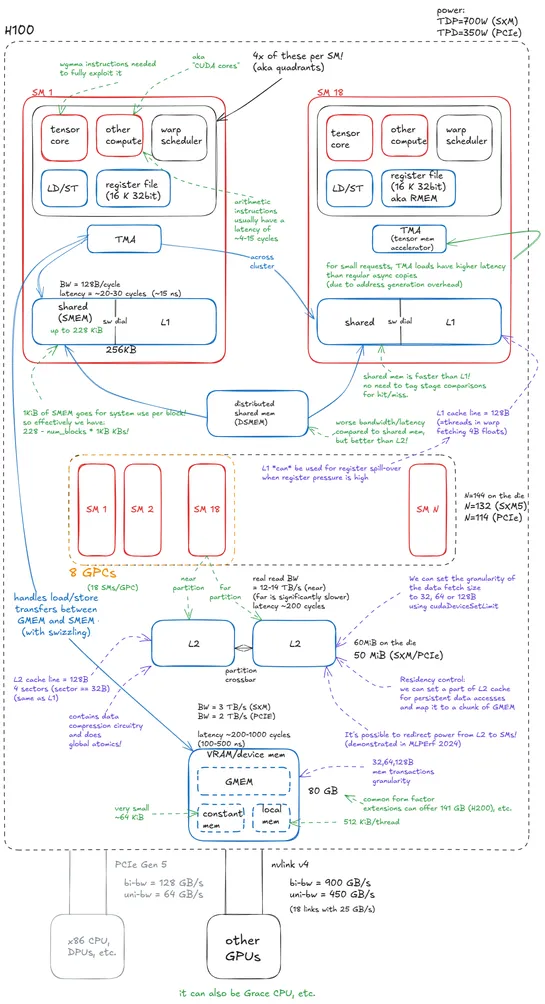
Inside NVIDIA GPUs: Anatomy of high performance matmul kernels
NVIDIA Hopper packs serious architectural tricks. At the core: **Tensor Memory Accelerator (TMA)**, **tensor cores**, and **swizzling**—the trio behind async, cache-friendly matmul kernels that flirt with peak throughput. But folks aren't stopping at cuBLAS. They're stacking new tactics: **warp-gro.. read more