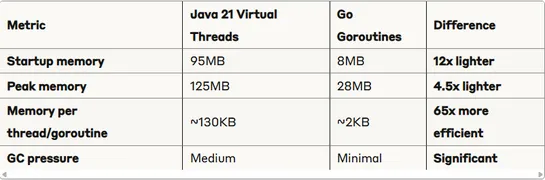
On-Call Burnout: What Incident Data Doesn’t Show
Incident dashboards measure system health, but rarely show the workload and strain engineers face when responding to alerts. Incident load isn’t only about the number of incidents, but the patterns surrounding them. In this article we explore these patterns and introduce On-Call Health, an open-source tool that analyzes engineering signals to surface early burnout trends, highlighting why incident volume alone isn’t enough and why after-hours interruptions, workload stacking, and long-term trends matter.