Jupyter Agents: training LLMs to reason with notebooks
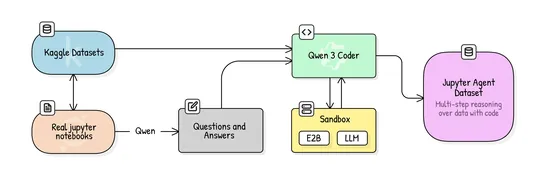
Hugging Face dropped an open pipeline and dataset for training small models—think **Qwen3-4B**—into sharp **Jupyter-native data science agents**. They pulled curated Kaggle notebooks, whipped up synthetic QA pairs, added lightweight **scaffolding**, and went full fine-tune. Net result? A **36% jump .. read more