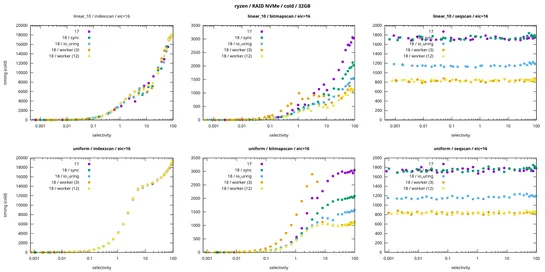
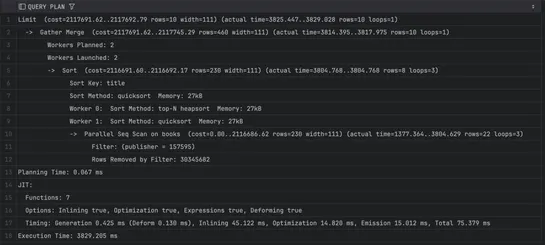
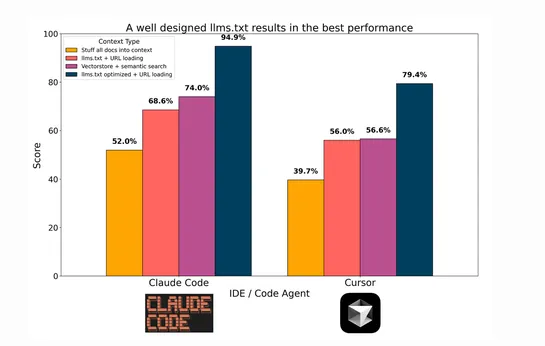
OpenAI Agent Builder: A Complete Guide to Building AI Workflows Without Code
OpenAI’sAgent Builderdrops the guardrails. It’s a no-code, drag-and-drop playground for building, testing, and shipping AI workflows - logic flows straight from your brain to the screen. Tweak interfaces inWidget Studio. Plug into real systems with theAgents SDK. Just one catch: it’s locked behind P.. read more