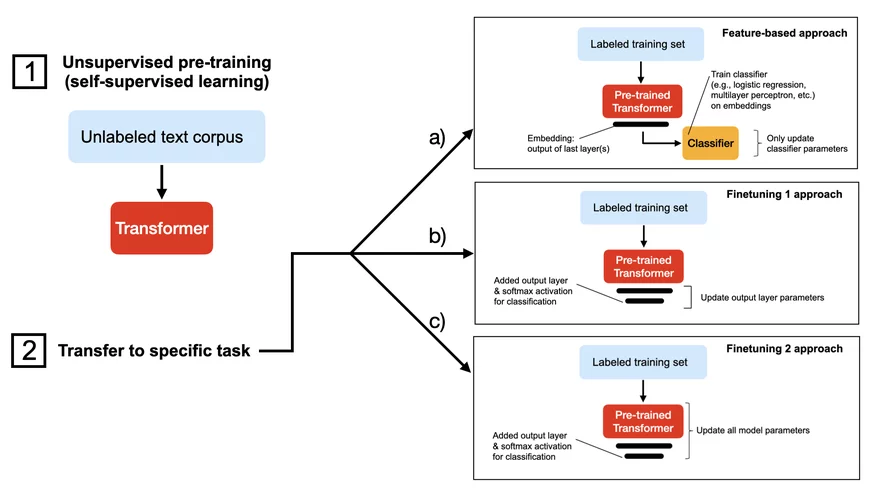
This blog post outlines techniques for improving the training performance of PyTorch models without compromising their accuracy.
The author uses a DistilBERT model to demonstrate various optimization techniques such as using the LightningModule and Trainer classes, automatic mixed precision training, static graphs with Torch.Compile, data parallelism via DistributedDataParallel, and the DeepSpeed and Fabric libraries.
By applying these techniques, the training time on a single GPU can be reduced by up to 8x without compromising the model's prediction accuracy. The author also provides code examples for each technique to demonstrate how it can be implemented.







Give a Pawfive to this post!
Share with your friends and followers
Start writing about what excites you in tech — connect with developers, grow your voice, and get rewarded.
Join other developers and claim your FAUN.dev() account now!








