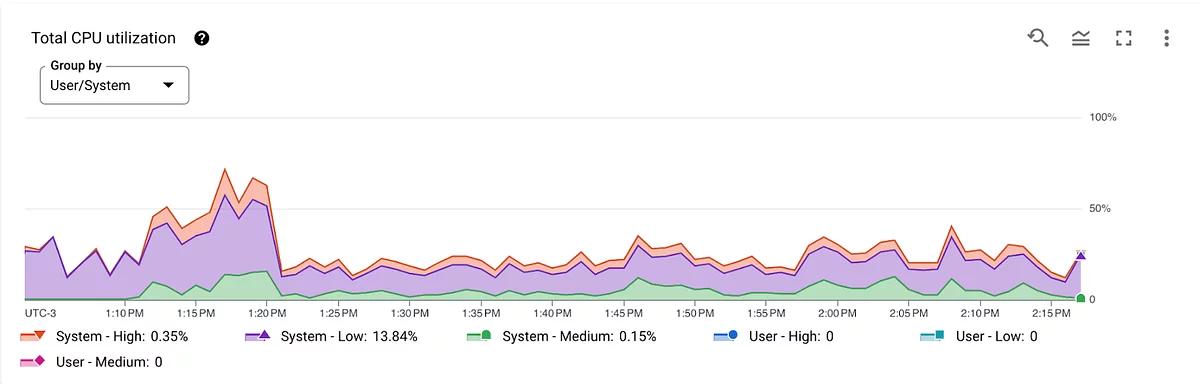
Additionally, reducing nodes during the process could cause up to 100% of total CPU utilization.
The study also confirms that Cloud Spanner defines parallelism degree and resource limit for index backfill based on instance node count and available CPU, and it is not possible to speed-up the index creation process by adding more resources.
The tests conducted in the study highlight the importance of careful planning and strategic decision-making when it comes to modifying indexes in Cloud Spanner.
Give this a Pawfive!
Share with your friends and followers







Start writing about what excites you in tech — connect with developers, grow your voice, and get rewarded.
Join other developers and claim your FAUN.dev() account now!








