







Ever wondered what goes on behind the scenes of our favorite content streaming service?
Well, you’re in luck as I will explain the Netflix backend on Amazon Web Services(AWS) and try to simplify it.
Netflix utilizes two cloud services namely Amazon Web services and Open Connect, both of which work smoothly to deliver us as the users exceptional viewing experience.
Open Connect is what Netflix uses as its content delivery network, and will not dive deep into the topic.
Client

Source: Reddigo
Netflix supports a wide range of devices ranges from smartphones, smart TVs, PCs, and their different operating systems.
It all starts with you pressing that click button and a request to the Netflix servers which are mainly hosted on AWS is made.
AWS Elastic Load Balancing
The request together with multiple other requests is forwarded to Amazon's elastic load balance to route to the traffic different EC2 instances.
The load is balanced across different zones which are known as the two-tier balancing scheme.
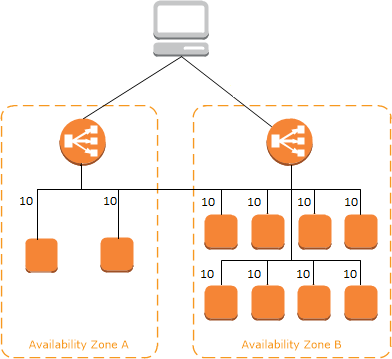
Source: Amazon Web Services
Before a video is made available, preprocessing takes place this ranges from finding errors, converting the video into a different format or resolution, etc, this is known as transcoding.
Transcoding is done to accommodate the various devices supported by the platform, as you can imagine a smartphone needs a smaller resolution and large devices such as smart TVs need a higher resolution.
Files are also optimized according to network speed, when your Internet Service Provider(ISP) is experiencing a slow network then the resolution might be decreased.
If you have very fast speeds, it is only fair that you receive your video in high resolution.
This is achieved by the creation of multiple copies of the same movie, in different resolutions.
A movie might be a 60GB file which is broken down into different chunks which are onboarded into a queue, as they exit the queue they are picked up by different EC2 workers and merged into Amazon S3.
ZUUL
This is a gateway service created by Netflix that provides dynamic routing and monitoring.

Diagram Illustrating the Zuul infrastructure
The request you sent from your device now hits the netty proxy, which sends it to the inbound filter and can be used for authenticating, routing, or decorating this request.
Following this, the request is sent to the end-point filter which is used to return as a static request or forward your request to the back-end services.
Once a response is received from a backend service, the endpoint filter will transfer it to the outbound filters.
The outbound filter performs a process known as GZipping on the content and adds or removes the header. Once the two processes are complete a response is sent back to the netty proxy.
Hystrix
With so many processes happening a fault tolerance mechanism is definitely needed.
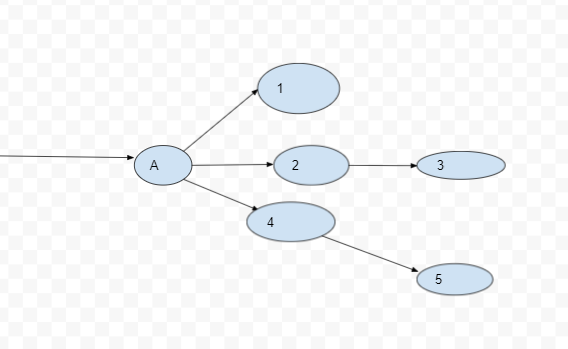
Diagram Illustrating Endpoints in a system
The above diagram illustrates endpoints in a system, if endpoints 4 and 5 throw errors then the whole system should not suffer, hence a hysterix is used to isolate endpoints.
Simply explained hysterix is an algorithm that decorates microservices also referred to as endpoints in a system.
Microservices

Diagram illustrating the different Microservices within Netflix
Microservices are key to powering the Netflix API infrastructure, as a user request comes in the call is made to any endpoint, moves on to the other end points through an iterative process.
The microservices can be distributed across different instances using HTTP or Remote Procedure Calls (RPC).
The common issue with a microservice-powered system is any node can fail and the entire system can cascade into failure, how do we control this?
As mentioned above one way is the hysterix algorithm which isolates end points and the other is reducing dependencies on vital nodes.
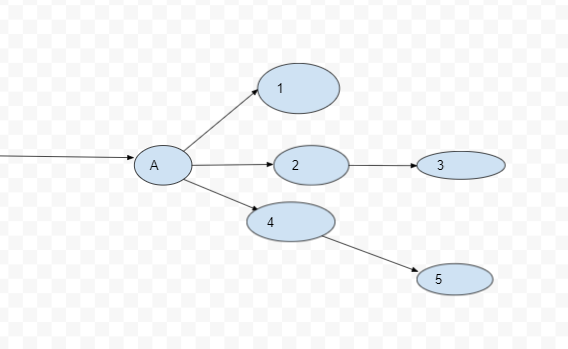
Diagram illustrating node A

Diagram illustrating node D
Above we have two diagrams, one is of Node A and its dependencies, and the other is Node D and its dependencies.
Comparing the two diagrams we can see that node A has multiple dependencies and Node B only one, hence Node D is the reliable and scalable node on which we can run important services.
With software engineering we should always look at the best and worst case, a system like Netflix crashing should mean at least basic functionalities are available for clients.
Critical endpoints such as search, play, navigation should always be allocated less dependencies.
Another key feature in a failsafe microservice system has stateless endpoints, if an endpoint is down then the user should get a response from any other node/endpoint.
EV Cache

Diagram illustrating an EV Cache system
EVCache is a custom caching layer owned by Netflix which is based on mamcache D and spymemcache D. It uses multiple clusters deployed on EC2 instances to reduce pressure on the end points.
When the client EVCache system receives reads and writes it distributes them to every node available in that cluster, this means the cache is distributed evenly within the network.
Database

Source: Apache Cassandra
Netflix utilizes two different database systems namely MySql and Apache Cassandra.
My SQL is a relational database management system(RDBMS) and Cassandra is NoSql system.
MySql is used to store user information such as billing information, transactions as these need asset compliance.
The rest of the data such as big data and user viewing history is stored in the Cassandra database system.
My SQL has been deployed on Amazon large EC2 instances using a NoDB master to master setup.

Diagram illustrating local and cross Datacentre high availability
When a write is made, it is also replicated to the other master node then only an update will be sent for queries that have been made to the master.
Replicas for each and every node are made to handle the scalability and reliability of the RDBMS, these replicas are available locally and across data centers.
When one master node fails DNS configurations is made to redirect queries to the right master.
Cassandra
Apache Cassandra earned its reputation as an open source no sql schema-less database system that can handle large amounts of data.
Netflix adopted this data base management system to handle their big data, as Netflix grew data began to pile up and fill Cassandra nodes.
The ratio of user reads to writes became 9 to 1 prompting the engineering team at Netflix to optimize the database system.
A scheduled job system was developed which separated data into the following; live viewing history and compressed viewing history, with live viewing history being the most recent.
The scheduled jobs compressed the old viewing history which is kept until needed for whatever purpose, recent viewing history is used for building machine learning models.
Apache Kafka and Chukwa
Apache Chukwa is used for collecting logs from distributed systems, it comes from the Hadoop scalability and robustness.
All logs and events from different parts(Hysterix and inbound filter) within the system are sent to Chukwa.
This data is then visualized and analyzed with the build-in dashboard. Chukwa forwards the data to Amazon S3 and a copy of this data is sent to Apache Kafka.
The data is then routed with Kafkas routing service to various synchronized mechanisms such as Amazon S3, elastic search, and other secondary Kafka.
Elastic Search
The events and logs flow through Chukwa, Kafka and the final stop is elastic search.
There are about 150 clusters and 3500 instances that handle elastic search on the AWS backend.
Practical use case of elastic search would be streaming errors experienced by clients; customer service can just search for the error using the customer's details and the error will be visualized, together with details of the error.
Elastic search can also be used to visualize; Sign up, login and keep track of usage.
See Also:
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/concepts.html
https://www.loginworks.com/blogs/how-netflix-use-data-to-win-the-race/
https://github.com/Netflix/Hystrix
https://github.com/Netflix/zuul
Share with your friends and followers
Start blogging about your favorite technologies, reach more readers and earn rewards!
Join other developers and claim your FAUN account now!

The Maths Geek 🤓
@thenjikubheka
User Popularity
619
Influence
62k
Total Hits
22
Posts






Read, Learn, Know, Teach
Hand curated newsletters for Developers, private Slack with like minded people, podcasts, job offers, news and more!

Only registered users can post comments. Please, login or signup.