Join us
@thenjikubheka ・ Nov 21,2021 ・ 6 min read・ 2k views ・ Originally posted on faun.pub








The success story of distributed systems starts with the social media platform we all love; Twitter.
Twitter has about 300 million plus users with a read/write ratio of 600 000 to 600, which further translates to 1:1000.
For a single tweet that is made, there are about a thousand people reading that particular Tweet.
Which leads us to the big question, how do we engineer a read-heavy system such as that of Twitter?
Data Flow
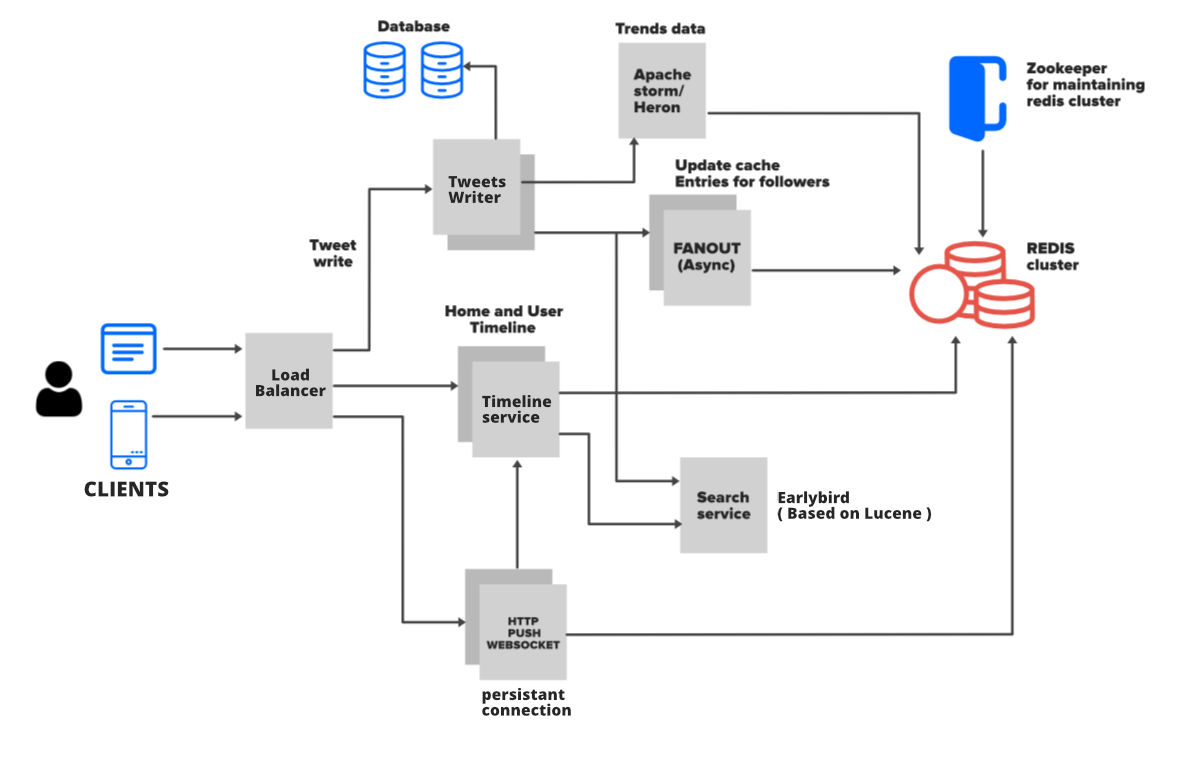
Source: GeeksforGeeks.org
There are three scenarios pertaining to data flow within a Twitter system namely; when a user tweets, when a user searches for a tweet, and tweets displayed on a timeline, be it home or user.
When A User Tweets
Tweets Used In Search Functions
Tweets Displayed On The Timeline
There are two types namely home and user timeline.
The home timeline displays the tweets made by people and accounts you follow, while the user timeline displays the tweets and retweets made by you.
Redis is an open-source in-memory cache system used for efficient scalability and cluster building.
Combined with the great power of Redis is a database with the following tables; user, tweet and followers, this will be stored in ourRDMS.

Diagram Illustrating User, Tweets and Followers Relationship
Whenever a user creates a profile we will have an entry into the database, under the user table.
When the user starts following a page or a person, we will have entries into the followers and user table with a 1 to may relationship between the user.
As the user familiarize themselves with Twitter, they begin to tweet, and entry is saved into the tweet table and user table with 1 to many relationships.
The 1 to many relationships ensures there is a copy of the tweet should the source tweet be deleted.

Source:commons.wikipedia.org
Traditional RDBMS will not be able to handle a read-heavy system such as Twitter, hence we integrate a tool such as Redis. Our data will be saved as follows inside Redis.
The first entry shows us the tweets the user has made thus far with the tweet_id entries and the second entry shows us the account the user is following so far with the follower_id entry.
User Timeline
You might ask, “How is the data used to generate the User Timeline?”
As a user tweets/retweets this data is continuously saved into Redis, ensuring that the data is easily retrievable should I or any other curious mind decide to visit/query my timeline.
These can be retrieved in Redis using USER_ID, coupled with the creation of a TWEETS_ID entry to fetch a specific tweet from Redis.
The data together with the metadata is used to compile the user timeline
Home Timeline
The API which loads the homepage should give a response within 200 milliseconds, to achieve this we need to use the fanout approach.
The fanout approach moves data from a single point to multiple destinations, in our case user timelines.
This approach reduces queries that have to be made when there is a request on the homepage of a particular user.

Diagram Illustrating users making a query on my Timeline from their home timeline
When I make a tweet, it is saved into the database, when a query is made the tweet is stored together with other tweets I made, the data is then pushed to all my followers' timelines.
The tweet is then updated to this person's homepage in the Redis list, and waiting for my followers to visit their home page. As soon as they do the tweet moves out from the list and is pushed to their timeline.
The list does not only contain my tweet but tweets of other people they follow who have tweeted before or after me, all these tweets are pushed to his timeline.
Celebrity Tweets
How would the system handle tweets from a user such as Barack Obama or Elon Musk?
Barack Obama currently leads the way with 129 million followers, this means when he Tweets all his 129 million followers should have the tweet updated to their timeline.
When President Obama tweets it is saved into the database and added to the user timeline cache.
I am one of the followers of Pres. Obama inside my list his tweet and those of others I follow is stored.
Before all the data is pushed to my timeline, the algorithm checks how many celebrity accounts am I following, then moves on to check the cache of each celebrity and checks for recent tweets.
All celebrity tweets are added to my tweet list together with the average people I follow, these are all pushed to my timeline.
Trending Topics
Trending topics / # is measured using the following principle; the volume of tweets and time taken to generate the tweets.
Topics such as #Jeff Bezon and #Trump generate thousands of tweets in a short amount of time. This is compared to #AI which will generate a hundred thousand tweets over a year, hence #AI is not a trending topic.
A stream processing framework such as Apache Storm is used to determine # in real-time.

Diagram illustrating data flow of a trending topic
When a tweet is made, the message enters the filter which is responsible for filtering out all tweets that violate Twitter regulation.
The message then moves to the parse operation which will match each tweet to a hashtag.
After this stage, the tweet is distributed into two parts; geolocation and trending. One process will handle geolocation processing and the other trending processing, a copy of the tweet is passed to both timelines.
It moves to the trending process to check if the topic has created multiple tweets in a short space of time. For this, we will use a window operation algorithm that checks the topics in minute window periods.
Once the rate is calculated according to the window period, the data is forwarded to the rank operator, which will assign each and every hashtag.
Now moving on to geo-location processing, filtering which hashtag belongs to which country.
A hashtag such as #tumisole and #karabomokgoko is relevant to the South African audience but will not mean much to a US audience. The geolocation operator sorts out trending topics according to location.
Both data streams are processed in real-time and sent to Redis, to be retrieved whenever needed.
Mobile Applications
To handle the Twitter mobile application for both iOS and Android, there is an HTTP web socket component that works in real-time.
ZooKeeper

Source: Apache
This open framework from Apache can be used for multiple purposes, by different organizations.
Twitter uses Zookeeper as a coordination service for distributed services such as; group services, configuration management, leader election the list goes on.
Source:
Share with your friends and followers
Join other developers and claim your FAUN account now!


Influence
Total Hits
Posts

Hand curated newsletters for Developers, private Slack with like minded people, podcasts, job offers, news and more!



