







Part 2
Implementing the Airflow HA solution
For simplifying installing process, I will perform all actions under root. You should use a non-privileged user with sudo for installing. We’ll skip this question as well as many security aspects.
1.1 Installing etcd and patroni
Let’s start the installation process by installing the PostgreSQL cluster with Patroni.
Prepare a node for installing necessary packages:
Configure your timezone:
Then install etcd from Ubuntu’s repos:
Then install patroni itself:
1.2 Installing PostgreSQL from the official repository
Installing PostgreSQL from the official repo allows us to install the latest stable version.
Just follow the instructions from the official website:
Remove all PostgreSQL data, installed from repository, because patroni cluster will create its own configs and databases:
Disable postgresql service, since the cluster will be started by patroni:
1.3 Configuring patroni, etcd, and PostgreSQL
Here is an etcd config template:
Just replace names and IP addresses with yours.
Then, take the following Patroni config and modify it with your data(please bear in mind it’s YAML and you should use the right indents):
Further, we need to allow connecting to our PostgreSQL instances from the local network:
I added the following two strings:
The lines above permit connection any of the PostgreSQL nodes from the local network. If you are not going to connect directly to the node, you can leave only a load balancer IP address.
Now the time has come to add systemd units for etcd and patroni:
You should enable these two services.
Note. As you have to install at least three nodes, there is a convenient way to install and configure the patroni cluster is to create an Ansible playbook(or use something similar).
Note. Pay attention, patroni depends on etcd, if etcd fails at the start, patroni also won’t be launched. Occasionally, it’s useful to avoid starting patroni on a specific node to perform some manual actions like database recovery. Take it into account!
1.4 Start PostgreSQL cluster with Patroni
First of all, service etcd should be running before starting Patroni, which will start PostgreSQL.
Start it:
The action above should be done on all three nodes
Let’s check if the etcd cluster is up:
If you got something like that, it means the etcd cluster has been built and running.
Master election and other cluster algorithms are implemented in etcd, and patroni relies on it.
To see which node is master, type in a console:
The next step is to start Patroni with PostgreSQL. When patroni is being launched, it automatically starts PostgreSQL, which in its turn, initializes the database, then patroni creates users specified in config, replaces pg_hba.conf file, postgresql.conf is renamed to postgresql.base.conf and finally, patroni adds postgresql.conf file with specific settings and with including postgresql.base.conf.
Therefore, if you need to change some of the PostgreSQL settings, let’s say timezone, you should modify postgresql.base.conf file.
Do it on all nodes!
Let’s check if PostgreSQL is up:
You’ll see patroni process like:
Moreover, you should see PostgreSQL processes.
Okay, it’s about the process, but how to check if the database cluster is working properly?
There is a command-line interface to patroni:
This utility is used for cluster managing (switchover, failover, etc) too. I won’t consider this.
1.5 Load balancer
One of the requirements is to use an HA load balancer. Usually, cloud providers supply load balancers and guarantee high availability.
During creating a load balancer what you should pay attention to:
- Service. Choose TCP service and specify ports 5432
- Health check. Choose HTTP, port 80, specify URL as
/masterfill in the response code field by 200.
Attach your LB to the local network, chosen targets should be your three nodes.
I’ll provide a few screenshots from Hetzner, other providers have the same settings, and interfaces look similar(AWS,GCP, etc).
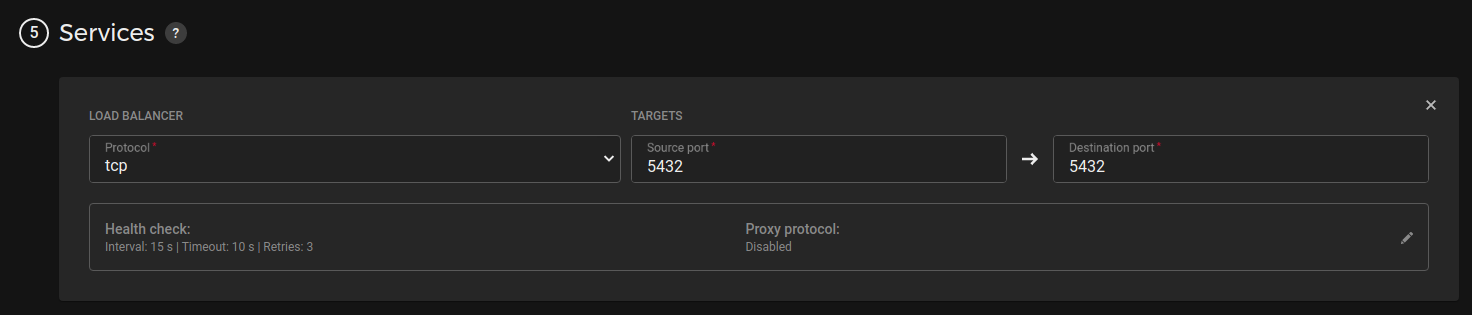
Pic 1. Load balancer services settings

Pic 2. Load balancer health check settings
Test your patroni cluster:
Where 10.5.0.10 is the load balancer’s IP address.
Admin’s password you can find in patroni config.
Create a user and database for airflow:
1.6 Celery
Celery can be installed from OS packages and from pip repository. A preferred approach is to install using pip:
You should install celery on all nodes.
Installed package no need to be configured.
1.7 RabbitMQ
To install RabbitMQ type in a console the following(on three nodes):
Then enable systemd unit:
and start it:
Then we need to configure the RabbitMQ cluster.
To configure the broker we’ll use CLI.
The following actions should be done on one node, say on node1:
where airflow is the user and cafyilevyeHa is its password
Now, let’s create the RabbitMQ cluster.
It’s important to add all nodes to /etc/hosts file:
Firstly, we need to activate ssh passwordless access between cluster nodes:
generate ssh keys and put them into authorized_keys files on all three nodes.
You can use once generated keys.
Copy cookies from any node to others(in the example below we use node1):
Cookies are used for authentication.
Check if nodes are working independently:
sequentially enter the command below to check the status of the cluster, you’ll see the cluster is not created:
After checking prerequisites, it’s time to add nodes to the cluster.
It’s necessary to perform the actions on node2 and node3:
When the cluster has been created, you can check its status:
As you’ve created the cluster, you’ll see something like this:
Also, there is a possibility to check the status in the web interface, create an ssh tunnel:
In your browser’s address line insert http://localhost:15672
You’ll see the state of the cluster and nodes.
Note. There is a way to enable peers auto-discovery, but it’s not the scope of the article.
See you in the third part of the tutorial.
Share with your friends and followers
Start blogging about your favorite technologies, reach more readers and earn rewards!
Join other developers and claim your FAUN account now!

Denis Matveev
sysadmin/devops, Ignitia AB
@denismatveev


User Popularity
106
Influence
11k
Total Hits
3
Posts

Read, Learn, Know, Teach
Hand curated newsletters for Developers, private Slack with like minded people, podcasts, job offers, news and more!

Only registered users can post comments. Please, login or signup.