






TL;DR
The Qwen3-TTS series introduces open-source models for speech generation, voice design, and cloning, available in 1.7B and 0.6B sizes. These models support 10 languages and offer features like rapid voice cloning and style control. They excel in multilingual capabilities and efficient speech signal processing.
Key Points
Highlight key points with color coding based on sentiment (positive, neutral, negative).The Qwen3-TTS model family supports multilingual speech generation across 10 languages, including Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, and Italian.
The released models are available in two sizes, 1.7B and 0.6B parameters, and include variants for voice design, custom voice control, and base voice cloning using short reference audio.
Qwen3-TTS supports both streaming and non-streaming speech generation, with reported end-to-end streaming latency as low as 97 milliseconds and first audio output after a single character.
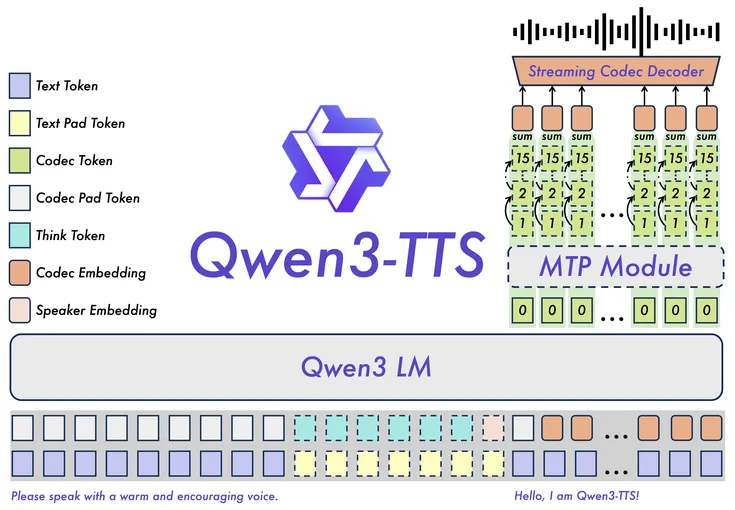
The Qwen3-TTS-Tokenizer-12Hz uses a multi-codebook speech encoding approach to achieve efficient acoustic compression while preserving paralinguistic and environmental speech features.
Tokenizer evaluations on LibriSpeech show strong reconstruction quality, with reported PESQ scores up to 3.68, STOI of 0.96, and high speaker similarity (near-lossless speech representation)
In multilingual voice cloning and long-form synthesis benchmarks, Qwen3-TTS reports low Word Error Rates and competitive speaker similarity scores compared to both open-source and closed-source TTS systems.
The Qwen3-TTS series has been released, introducing a new set of open-source models for speech generation, voice design, and voice cloning. The series includes two model sizes, 1.7 billion and 0.6 billion parameters, and is built on the Qwen3-TTS-Tokenizer-12Hz. This tokenizer is designed for efficient acoustic compression and high-dimensional semantic modeling of speech signals, preserving paralinguistic information and acoustic environmental features while enabling high-speed, high-fidelity speech reconstruction.
The models support ten mainstream languages, including Chinese, English, and Japanese, as well as multiple dialects. They offer capabilities such as voice design from natural language descriptions, style and timbre control, and rapid voice cloning from as little as three seconds of reference audio. Using short speaker samples, the models can capture speaker characteristics while adapting tone, rhythm, and emotional expression based on textual instructions and semantic context.
Qwen3-TTS is designed to operate in both streaming and non-streaming modes, with low end-to-end latency suitable for real-time interactive applications. In streaming scenarios, speech generation can begin almost immediately which makes it applicable to conversational agents and live voice interfaces.
Within the model lineup, the 1.7B parameter variant targets peak performance and fine-grained control, while the 0.6B variant emphasizes a balance between quality and computational efficiency. Across tasks such as voice design, voice control, and multilingual voice cloning, the models report strong performance, including competitive Word Error Rates and speaker similarity scores relative to existing systems.
The Qwen3-TTS-Tokenizer has been evaluated independently for speech reconstruction quality, achieving high scores on metrics such as PESQ and STOI, indicating clear and intelligible audio reconstruction. The full Qwen3-TTS model family is now open-sourced and available via GitHub and the Qwen API, providing developers with a comprehensive toolkit for speech synthesis, voice cloning, and controllable voice generation.
Key Numbers
Present key numerics and statistics in a minimalist format.The size of the larger Qwen3-TTS model.
The size of the smaller Qwen3-TTS model.
The number of languages supported by the Qwen3-TTS models.
The end-to-end synthesis latency of the Qwen3-TTS models.
The PESQ score for wideband audio quality of the Qwen3-TTS models.
The PESQ score for narrowband audio quality of the Qwen3-TTS models.
The STOI score indicating intelligibility of the Qwen3-TTS models.
The UTMOS score of the Qwen3-TTS models.
The WER for single-speaker multilingual generalization of the Qwen3-TTS models.
The WER for Chinese during continuous 10-minute synthesis of the Qwen3-TTS models.
The WER for English during continuous 10-minute synthesis of the Qwen3-TTS models.
The WER on the TTS multilingual test set across 10 languages for the Qwen3-TTS models.
The speaker similarity score for speaker information preservation of the Qwen3-TTS models.
The speaker similarity score on the multilingual test set for the Qwen3-TTS models.
The style control score achieved on InstructTTS-Eval by the Qwen3-TTS models.
Stakeholder Relationships
An interactive diagram mapping entities directly or indirectly involved in this news. Drag nodes to rearrange them and see relationship details.Organizations
Key entities and stakeholders, categorized for clarity: people, organizations, tools, events, regulatory bodies, and industries.Qwen is a research group focused on developing large-scale language, multimodal, and speech models, including open-source model families for text, vision, and audio generation.
Alibaba Cloud is a cloud computing platform providing infrastructure, AI services, and model hosting, and offers API access to Qwen models.
Tools
Key entities and stakeholders, categorized for clarity: people, organizations, tools, events, regulatory bodies, and industries.Qwen3-TTS is a family of open-source text-to-speech models designed for speech synthesis, voice cloning, voice design, and controllable speech generation across multiple languages.
Qwen3-TTS-Tokenizer is a multi-codebook speech tokenizer used to encode and reconstruct speech signals, preserving acoustic and speaker characteristics for downstream speech generation models.
The Qwen API provides programmatic access to Qwen models for inference and integration into applications via cloud-based endpoints.
Additional Resources
Enjoyed it?
Get weekly updates delivered straight to your inbox, it only takes 3 seconds!Subscribe to our weekly newsletter Kala to receive similar updates for free!
Give a Pawfive to this post!
Share with your friends and followers
Start writing about what excites you in tech — connect with developers, grow your voice, and get rewarded.
Join other developers and claim your FAUN.dev() account now!
")
FAUN.dev()
FAUN.dev() is a developer-first platform built with a simple goal: help engineers stay sharp without wasting their time.







Kala #GenAI
FAUN.dev()
@kalaFeatured Course(s)

Cloud-Native Microservices With Kubernetes - 2nd Edition
A Comprehensive Guide to Building, Scaling, Deploying, Observing, and Managing Highly-Available Microservices in Kubernetes


Observability with Prometheus and Grafana
A Complete Hands-On Guide to Operational Clarity in Cloud-Native Systems
