OpenTelemetry Spans Explained: Deconstructing Distributed Tracing
Understand how OpenTelemetry Spans capture, connect, and explain every operation in your distributed system for deeper visibility.

Understand how OpenTelemetry Spans capture, connect, and explain every operation in your distributed system for deeper visibility.

Compare top APM tools for Node.js — from open-source options to enterprise-grade platforms — and choose the best fit for your stack.

Explore the top Ruby APM tools for 2025 — from open-source to enterprise — to monitor, trace, and optimize your app’s performance.

Explore 11 APM tools built for Go—from lightweight open-source options to enterprise-grade platforms that simplify debugging.

Compare 15 PHP APM tools for 2025 — from open-source options to managed platforms — and find what fits your performance needs.
OpenTelemetry auto-instrumentation uses runtime hooks and agents to collect telemetry without code changes—covering most modern stacks.

Learn how to scale Prometheus APM for growing systems with practical strategies to keep queries fast and monitoring efficient.

Understand observability vs visibility: visibility shows current states, while observability uncovers why systems act the way they do.

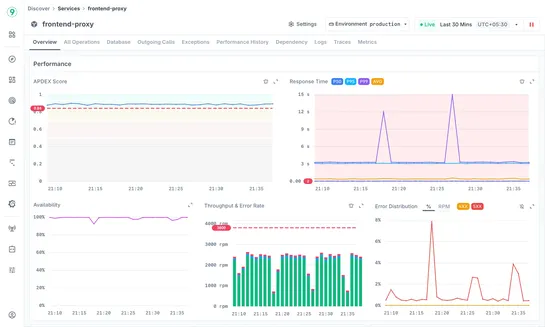
New services deploy faster than you can track them. Discover Services auto-discovers your entire architecture from traces—convention over configuration. No manual catalogs.
Understand how to name spans, attributes, and metrics in OpenTelemetry for consistent, queryable, and reliable observability data.


