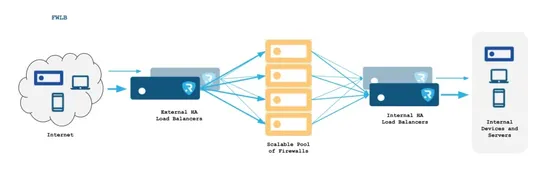
🔒 How can you improve the high availability and performance of your firewalls?
We're sharing a diagram on Firewall Load Balancing, along with a link to our technical article that explains how it works, its benefits, and best practices. 👉https://www.relianoid.com/resources/knowledge-base/misc/what-is-firewall-load-balancing-fwlb/ #FirewallLoadBalancing#HighAvailability#NetworkS..