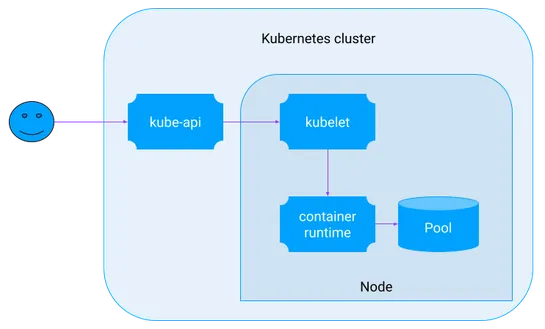
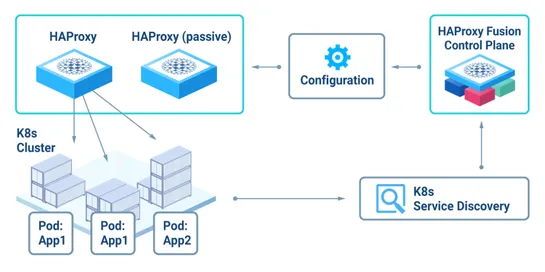
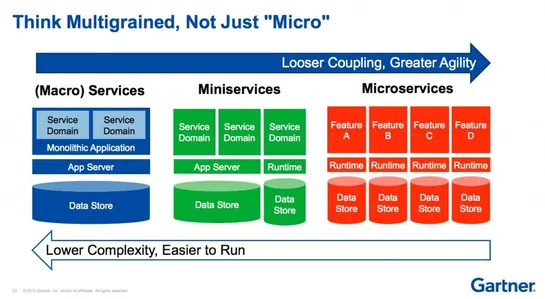
Partitions, Sharding, and Split-for-Heat in DynamoDB
DynamoDB starts to grumble when a single partition gets hit with more than 1,000WCU. To dodge throttling, writes need to fan out across shards. Recommended move: start with10 logical shards. WatchCloudWatch metrics. DialNup or down. Letburstandadaptive capacitybuy you breathing room - untilSplit-for.. read more