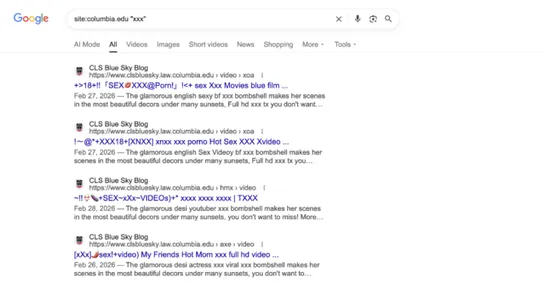
Why are top university websites serving p0rn? It comes down to shoddy housekeeping.
Researcher Alex Shakhov found scammers commandeering staleCNAMErecords. They hijack university subdomains (eg.berkeley.edu,columbia.edu,washu.edu) and serve p0rn and scam pages. Shakhov found hundreds of abused subdomains across at least34universities. He counted thousands of hijacked pages indexed .. read more