The State of OCI Artifacts for AI/ML
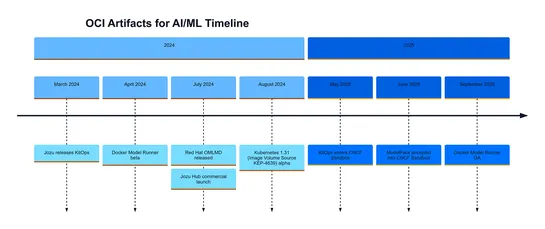
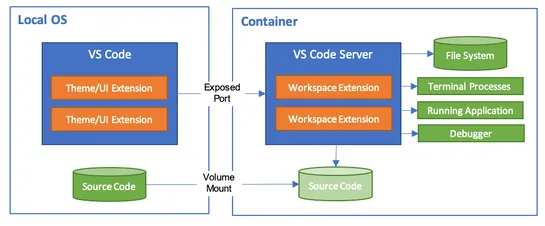
OCI artifacts quietly leveled up. Over the last 18 months, they’ve gone from a niche hack to production muscle for AI/ML workloads on Kubernetes. The signs? Clear enough:KitOpsandModelPacklanded in the CNCF Sandbox. Kubernetes 1.31 got native support forImage Volume Source. Docker pushedModel Runner.. read more