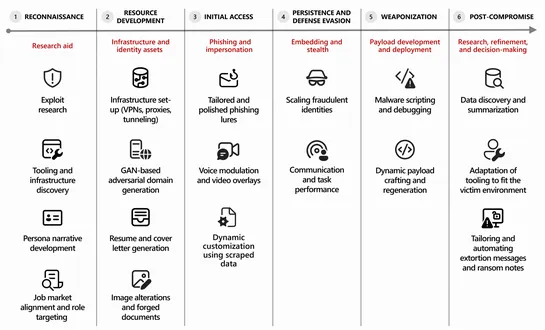
The great migration: Why every AI platform is converging on Kubernetes
The CNCF survey finds82%of container users runKubernetesin production.66%of GenAI hosts use it for inference. Kubernetes now stitches data processing, distributed training, LLM inference, and autonomous agents viaSpark,Kubeflow,Kueue,KServe, andArmada. GPU sharing and scheduling advanced withMIG, ti.. read more