Finally: AI Image Generation That Handles Text Correctly - Meet Nano Banana Pro

Google DeepMind introduces Nano Banana Pro, an advanced image generation and editing model, enhancing creative capabilities and available globally in the Gemini app.
Join us

Google DeepMind introduces Nano Banana Pro, an advanced image generation and editing model, enhancing creative capabilities and available globally in the Gemini app.
Cline-bench launches to offer realistic AI coding benchmarks, pledging $1M to support open source maintainers and enhance research with real-world challenges.
We're excited to attend Next IT Security – C-Suites Edition: Redefining Cyber Resilience in DACH, taking place on November 27th, 2025. “The time is always right to do what is right.” – Martin Luther King Jr. This exclusive summit brings together top CISOs, CTOs, and cybersecurity leaders from across..


Auto-discovery tools now detect services as they appear and build dashboards instantly. Here are seven platforms that do it well.


Pro tips to write dockerfiles. Cut your build timing of your images by half.

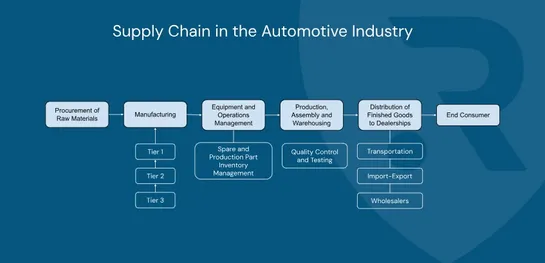
The major cyberattack that halted Jaguar Land Rover’s production for almost six weeks has exposed a hard truth: modern automotive manufacturing is deeply vulnerable to digital disruption. From frozen assembly lines to supplier chaos and regional economic fallout, the incident showed how quickly a si..
Understand how AWS Fargate runs your ECS containers without servers—just define CPU, memory, and networking, and AWS handles the compute.


Helm v4 has been released a week ago. Its highlights are: - Server-Side Apply instead of 3-Way Merge - WASM plugins - Using kstatus for resource tracking - Content-based chart caching This articleprovides a detailed overview of why these changes were made in Helm v4 and what they bring for Helm user..
Today we highlight our main diagram “Airport Software Systems”, showcasing how integrated airport management platforms —from AODB to landside & airside operations, billing, and information systems— work together to ensure efficient and secure airport operations. We also explain how load balancing en..

OTLP 1.9.0 adds support for maps, arrays, and byte arrays across all OTel signals. Here's when to use complex attributes and when to stick with flat.


