DeepSeekMath-V2 Launches with 685B Parameters - Dominates Math Contests

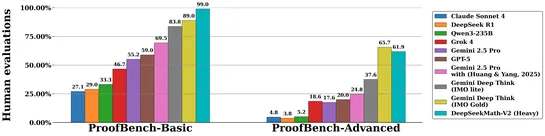
DeepSeekMath-V2, an AI model with 685 billion parameters, excels in mathematical reasoning and achieves top scores in major competitions, now available open source for research and commercial use.