Learn Git in a Day

Everything you need, nothing you don't
Join us




Have to manage Kubernetes in production but don’t feel confident about its many moving parts, complex architecture, and configurations? Here’s a selection of technical guides from experienced engineers for Kubernetes beginners looking to master this orchestration tool for running containerised apps efficiently and reliably.


A practical breakdown of the most common Spring Boot performance bottlenecks — and how we optimized our API from 3 seconds to 200 ms.

Microsoft's Project Silica encodes data in borosilicate glass using femtosecond lasers, offering long-term storage for up to 10,000 years. This method overcomes traditional storage limitations and is cost-effective, though write speed remains a challenge. The research phase is complete, but no product release has been announced.


California's Digital Age Assurance Act mandates operating systems to share users' age data with app developers via a real-time API by 2027. The law faces criticism for depending on self-reported ages, potentially affecting its efficacy.
A developer ditches the laptop and SSHs from an iPhone into an always-onMac Mini. The phone becomes a terminal and browser. The remote runs the dev server, theClaude Code/CodexCLI, hot reload, file watching, and pushes viaTailscale. Persistent sessions (tmux) keep AI agents and services alive across.. read more

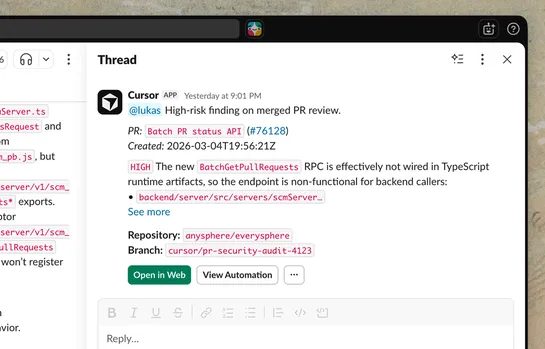
Agents trigger from schedules, Slack, Linear, GitHub, PagerDuty events, or customwebhooks. They spin upcloud sandboxes. They run configuredMCPsand models. They verify outputs. They use amemorytool. Cursor automates security audits on pushes. Scores PR risk and auto-approves low-risk changes. Runs Pa.. read more
The author supervises AI agents that orchestrate concurrent graph traversal, multi-layer hashing, AST parsing, and file system watchers. The agents run traversal, hashing, and watcher loops. The engineer architects system behavior, verifies outputs, and probes agents in parallel to debug... read more

AI hiring has split dev work into three camps:Apex Tier,Hybrid Middle, and a shrinkingAutomatable Tail. Demand now favorsAI orchestration,prompt engineering, fastcode reading, and platform roles likeplatform engineer,fleet supervisor, andAI QA. System shift:Organizations must rework career ladders, .. read more


