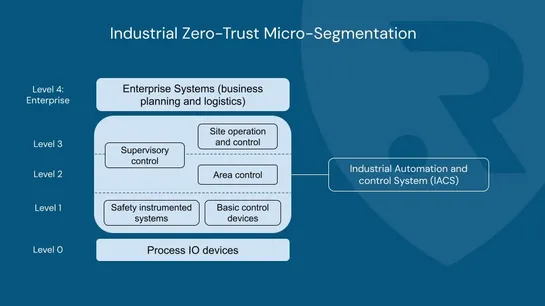
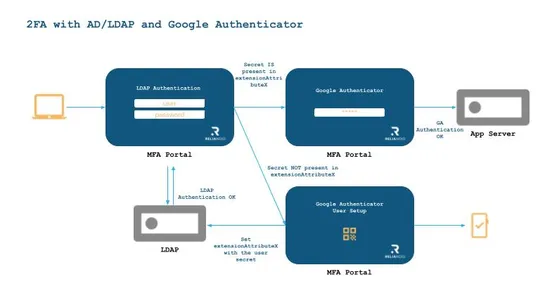
🚨 Is Your Business Ready for a Cyber Crisis? 🚨
A cyberattack can strike at any time—causing operational disruption, financial loss, and reputational damage. Preparing for and effectively managing a cyber crisis is no longer optional—it's essential. At RELIANOID, we help businesses build robust cyber resilience through advanced solutions and expe..