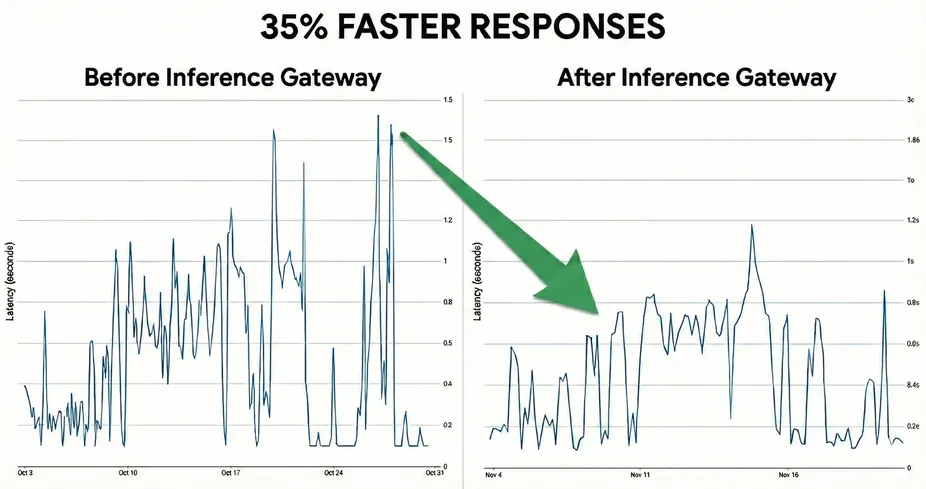
Vertex AI now plays nice with GKE Inference Gateway, hooking into the Kubernetes Gateway API to manage serious generative AI workloads.
What’s new: load-aware and content-aware routing. It pulls from Prometheus metrics and leverages KV cache context to keep latency low and throughput high - exactly what high-volume inference demands.









