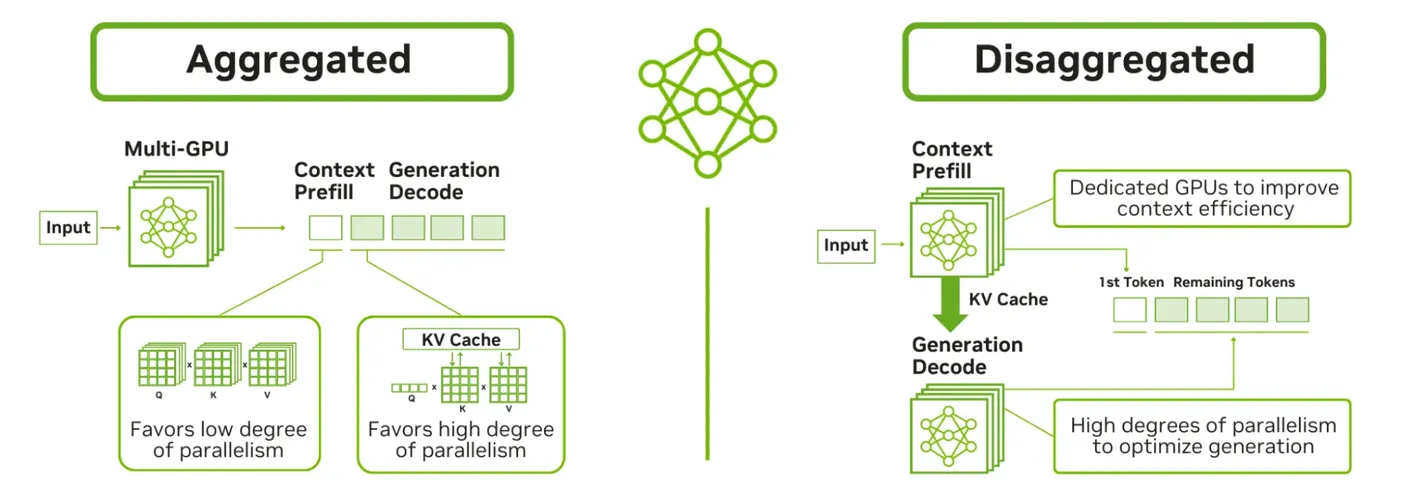
In large language model (LLM) inference workloads, a single monolithic serving process can hit its limits due to different compute profiles for prefill and decode stages. Disaggregated serving splits the pipeline into distinct stages to better utilize GPU resources and scale more flexibly on Kubernetes. Different ecosystem solutions like NVIDIA Dynamo and llm-d implement this pattern to optimize inference performance.







Give a Pawfive to this post!
Share with your friends and followers
Start writing about what excites you in tech — connect with developers, grow your voice, and get rewarded.
Join other developers and claim your FAUN.dev() account now!

Kaptain #Kubernetes
FAUN.dev()
@kaptainKubernetes Weekly Newsletter, Kaptain. Curated Kubernetes news, tutorials, tools and more!

Developer Influence
21
Influence
1
Total Hits
145
Posts
