Why GPUs accelerate AI learning: The power of parallel math
Modern AI eats GPUs for breakfast - training, inference, all of it. Matrix ops? Parallel everything. Models like LLaMA don’t blink without a gang of H100s working overtime... read more

Modern AI eats GPUs for breakfast - training, inference, all of it. Matrix ops? Parallel everything. Models like LLaMA don’t blink without a gang of H100s working overtime... read more

AWS has launched Project Rainier, a massive AI compute cluster with nearly half a million Trainium2 chips, in collaboration with Anthropic to advance AI infrastructure and model development.

LangChain raised $125 million to enhance its agent engineering platform, introducing LangChain and LangGraph 1.0 with new tools like the Insights Agent and a no-code agent builder, aiming to transform LLM applications into reliable agents.

Red Hat and NVIDIA partner to distribute the NVIDIA CUDA Toolkit across Red Hat platforms, aiming to simplify AI adoption and enhance developer experience.
Generative AI is snapping the attribution chain thatcopyleft licenseslike theGNU GPLrely on. Without clear provenance, license terms get lost. Compliance? Forget it. The give-and-take that powersFOSSstops giving - or taking... read more

A 10-node Raspberry Pi 5 cluster built with16GB CM5 Lite modulestopped out at325 Gflops- then got lapped by an $8K x86 Framework PC cluster running4x faster. On the bright side? The Pi setup edged out in energy efficiency when pushed to thermal limits. It came with160 GB total RAM, but that didn’t h.. read more

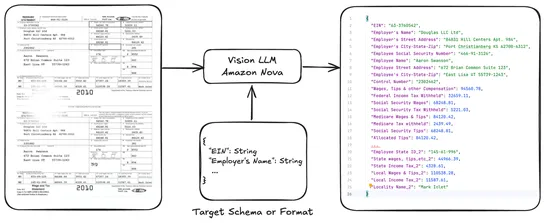
Amazon rolled out fine-tuning and distillation forVision LLMslike Nova Lite viaBedrockandSageMaker. Translation: better doc parsing—think messy tax forms, receipts, invoices. Developers get two tuning paths:PEFTor full fine-tune. Then choose how to ship:on-demand inference (ODI)orProvisioned Through.. read more