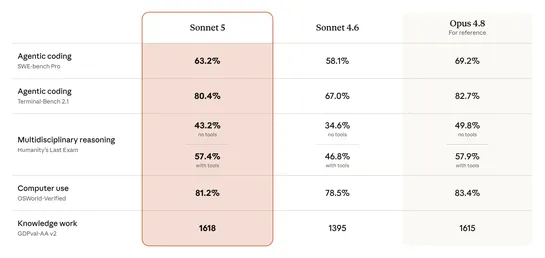
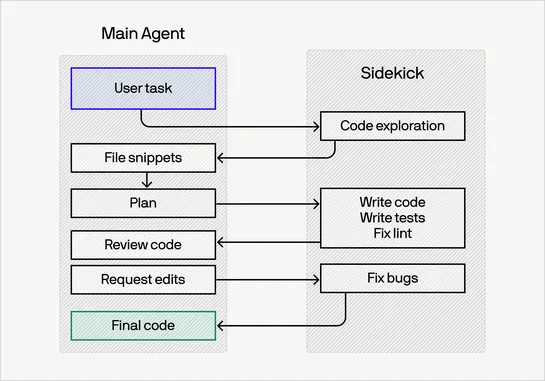
Kubernetes Deep Dive: QoS, Eviction, HPA, Probes, and Sidecars
An advanced 10-question quiz on Kubernetes internals and runtime behavior, aimed at practitioners who run clusters in production. It targets the subtle traps: QoS assignment rules, OOM-kill vs eviction, whether node-pressure eviction honors PodDisruptionBudgets, the exact HPA scaling formula and …