







When and how to use Amazon Aurora Serverless databases?
When we talk about the managed relational database services inside AWS, currently two primary services support different kinds of workloads, for different use cases. They are Amazon RDS and Redshift.
- Amazon Relational Database Service (RDS): RDS is the managed structured relational database service within AWS. Currently, supported database engines within RDS are Amazon Aurora, PostgreSQL, MySQL, MariaDB, Oracle and Microsoft SQL Server. Different versions of each of these supported engines are available inside RDS. We should use RDS when we want to support regular OLTP workloads with fixed schemas and the need for strong ACID transaction compliance.
- Amazon Redshift: Redshift is a managed data warehouse inside AWS that supports structured and semi-structured kinds of data for our OLAP analytical kind of workloads.
Within RDS, one of the databases engines supported is Amazon Aurora which was custom built by AWS with high performance and scalability in mind. It currently supports API compatibility with MySQL and PostgreSQL.
The main selling point for Amazon Aurora is that it provides most of the features of traditional commercial databases at a fraction of the cost of those commercial databases along with the ease of use and deployment of the cloud. It provides improved performance and scalability by separating the compute and the storage layers within the database that way they both can be scaled separately.
It currently supports up to 15 replicas per database instance, with the writer and replica database instances sharing the same storage layer. Any of these replicas can be configured to be automatically promoted to become the new primary DB instance, in case the original primary instance happens to go down for some reason.
In addition, Amazon Aurora saves multiple copies of the data across 3 availability zones inside the storage layer for high availability. The storage layers support autoscaling up to 64 TiB. I can go on and on about the features available within Amazon Aurora, but I’ll save that for another article.

Amazon Aurora DB Architecture
The main focus of this article is the Serverless offering inside Amazon Aurora. I think the word ‘Serverless’ is a bit overloaded.
Actual servers are running somewhere within an AWS data centre that are running our databases, just that we don’t have to worry about standing up and managing those servers, unlike provisioned RDS databases where we need to select the database instance class to run our databases on.
Aurora Serverless Features and Use Cases
So, you might ask, what are the major selling points for Aurora Serverless? Let me spell it out for you:
- It is a fully managed instance, and there is no capacity planning needed in advance before we provide a database instance.
- The database computer automatically pauses when there is no load and turns back on again when the load starts coming in again, that way we do not have to pay for the unused database compute capacity when there is no demand, and that should bring down the overall cost of using the service.
- Aurora Serverless is a great option for patchy workloads that have periods of usage interspaced with periods when there would be no demand on the database. The typical use case would be for developer and testing workloads where databases are used during office hours over the weekdays and apart from those times, these databases won’t be used much. So, during the periods when these databases are not being used they would automatically pause, and not cost us for the database compute capacity. One point to note is that even though the database computes will be paused during periods of no demand, the data itself will not be lost and it will be preserved.
- If we do not use Aurora Serverless, and instead if we are running our databases on EC2 instances, then for a similar use case we will have to execute Lambda functions on a schedule to turn off and turn on the database EC2 instances or we will have to create a schedule inside an EC2 auto-scaling group to do the same for us. As you can see, all of this will require more management overhead compared to just using Aurora Serverless.
- The compute and storage for an Aurora Serverless database will auto-scale based on demand. AWS just released the new Aurora Serverless v2 which can auto-scale compute in a matter of milliseconds based on application load, though Aurora Serverless v2 is still in preview. Also, unlike provisioned databases, we do not have to provide any storage capacity in advance, it will be taken care of by Aurora Serverless. For compute capacity auto-scaling Aurora Serverless uses something called Aurora Capacity Units (ACUs), which is equated to database instance memory allocation. We can define a maximum and minimum range for ACUs for our Serverless database and the compute will automatically scale up and down inside that range. One thing to note here is that for prolonged periods of no activity we can still configure the database compute to pause.
- AWS maintains a fleet of pre-warmed compute instances which will be added and removed from our fleet of database compute instances in a matter of milliseconds, based on demand. AWS also maintains a fleet of proxy compute instances for Aurora Serverless databases and when we connect to an Aurora Serverless database we connect to one of these proxies which redirects our connections to the actual Aurora Serverless compute instances if there is one available. Otherwise, it waits for a pre-warmed database compute instance to be get allocated to our database. One point to note here is that all the compute instances provisioned will be inside the same AZ, unlike the actual data storage layer which would be spread out across AZs. In case if the complete AZ running our Aurora Serverless databases happens to go down for some reason, AWS will automatically bring up new Aurora Serverless databases for us in a different AZ, albeit with some delay.
Aurora Serverless Database Provisioning and Usage
Now let’s get our hands dirty and let’s stand up an Aurora Serverless database from inside the AWS console.
While creating a new RDS database from inside the AWS console, when we select ‘Amazon Aurora’ as the engine, we can see the ‘Serverless’ option inside the capacity type.

Aurora Serverless Instance Creation
We can select the Maximum and Minimum ACUs between which we want to scale the Aurora Compute Capacity. The maximum ACU that we can get as of this writing is 256 ACUs which equates to 466 GiBs of RAM. As we can see in the below screenshot, it is a multiple of 2 GiB RAM and appropriate CPU units for that amount of RAM. We can also select if we want to scale the compute capacity down to 0 ACUs after a configurable period of inactivity which can be up to 24 hours.
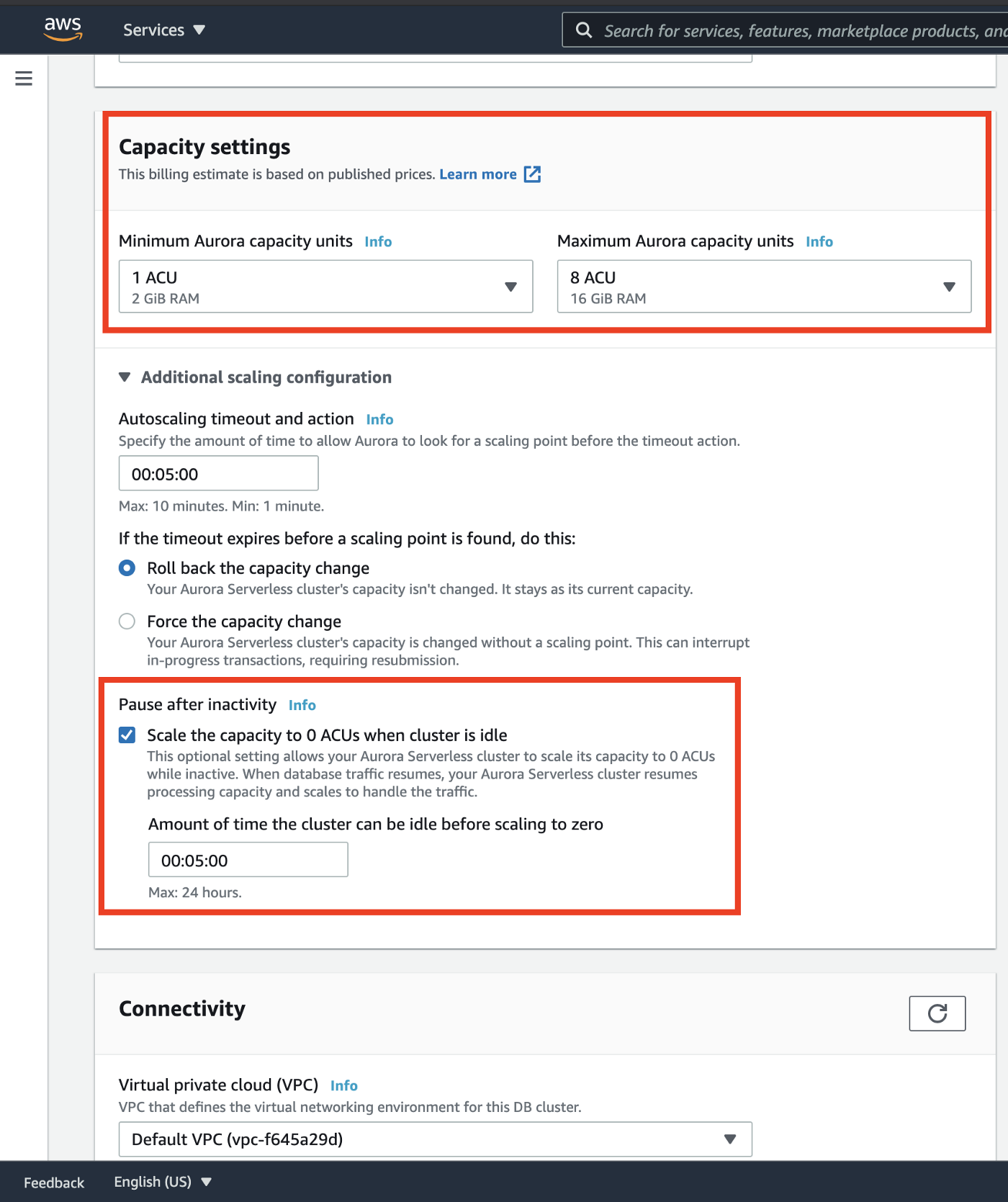
Aurora Serverless Database Capacity and Pause Settings
One other setting that I would like to highlight, is the ‘Data API’ setting inside ‘Web Service Data API’. When we enable this setting, then we can interact with the database directly over a Web API endpoint without the need to connect to the database. It also enables running queries directly against the database from inside the AWS console, as we will practically see later.

Aurora Serverless Database Data API Setting
One thing you will notice during Aurora Serverless database provisioning is that the database creation process is quite fast, it should take only about a minute or two for the actual database creation.

Aurora Serverless Database Created
Now let’s try to connect to this newly created database from right inside the AWS RDS console, by clicking on ‘Query Editor’ inside the left menu, putting in the database connection details in the resulting pop-up and then clicking on ‘Connect to Database’.
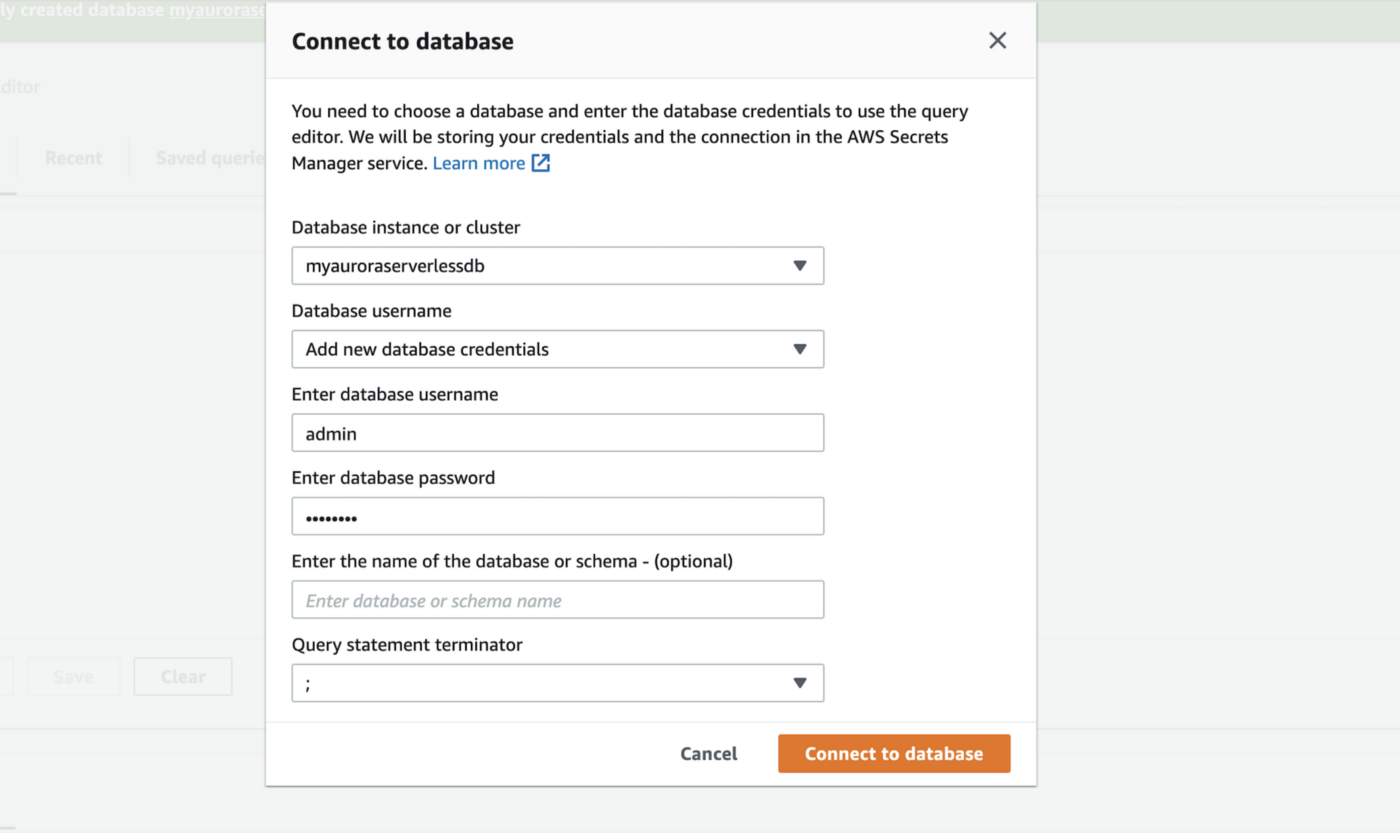
Once we are successfully authenticated and connected to the database we will be presented with a query editor right inside our browser, where we can type and execute queries directly against our Aurora Serverless databases. We can also get a listing of recently executed and saved queries.

We can also use the AWS CLI and the AWS SDKs in any of the supported programming languages to interact with the Aurora Serverless databases. I think Aurora Serverless would be an ideal candidate backend relational database for Lambda functions.
Pricing
Now let’s talk about the Aurora Serverless pricing. Aurora Serverless is going to cost us a flat $0.06 per ACU Hour. That should result in quite a bit of cost-saving for us as we do not need to pay for our database compute instances running at all times.
Conclusion
All in all, I can say that Aurora Serverless is a good option when we want to provision a cloud database for supporting sporadic workloads. Databases for supporting developer and testing workflows is an ideal candidate use case. Saving costs on such non-production workloads should be of concern to us. Below are links to AWS documentation related to Aurora Serverless, in case you need more information.
https://aws.amazon.com/rds/aurora/serverless/
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/aurora-serverless.html
What are you waiting for? Let’s start using Aurora Serverless for our developer and testing workloads and start saving!
Thank you for reading.
Share with your friends and followers
Start blogging about your favorite technologies, reach more readers and earn rewards!
Join other developers and claim your FAUN account now!


User Popularity
144
Influence
14k
Total Hits
3
Posts


Read, Learn, Know, Teach
Hand curated newsletters for Developers, private Slack with like minded people, podcasts, job offers, news and more!

Only registered users can post comments. Please, login or signup.